7 No sky is the best sky
There is no magic trick to extract neat, semantically homogeneous clouds from the wild sea of corpus attestations. As we have seen in Chapter 5, the clouds can take a number of different shapes, depending on the variability of the context words that co-occur with the target, their frequency and their diversity. Chapter 6 further shows that these clusters may have various interpretations, both from a syntagmatic perspective and from a paradigmatic perspective, resulting in a diverse net of phenomena. It also explores the role of the similarity and co-occurrence between the context words. In this chapter, we will look at the relationship between these results and the parameter settings that produce them.
In consonance to the previous analyses, there is no golden law to be drawn from here. There is no set of parameter settings that reliably returns the best output: not for specific parts of speech, nor for specific semantic phenomena. This variability will be illustrated in two sections: in Section 7.1 I will compare the medoids of hoop ‘hope/heap’ and stof ‘substance/dust…’ that best model homonymy in each lemma, while Section 7.2 will look at the shape that the same parameter configuration takes in many different models.
7.1 A pile of dust
As mentioned in Chapter 4, we have modelled 7 homonymous and polysemous nouns, with the intention of studying the relationship between parameter settings and granularity of meaning. We expected certain parameters to be better at modelling differences between homonyms and others to be able to capture, at least in some cases, the more subtle differences between senses of a homonym. However, even though homonymy should be relatively easy to model48, the results are not so straightforward. As an example, let’s look at the medoids of hoop ‘hope, heap’ and stof ‘substance, dust…’ that most successfully model the manual annotation.
Figure 7.1 shows the best medoid of each of the lemmas, in terms of semantic homogeneity of the clusters. By mapping the sense tags to colours, we can see that each of them has a rather well defined, homogeneous area in the t-sne plot. It should be noted, however, that the areas are relatively uniform, and we would be hard pressed to find such a clear structure without any colour-coding. In fact, hdbscan only highlights the most salient areas, covering, for example, only the center of the light blue island in the left plot.
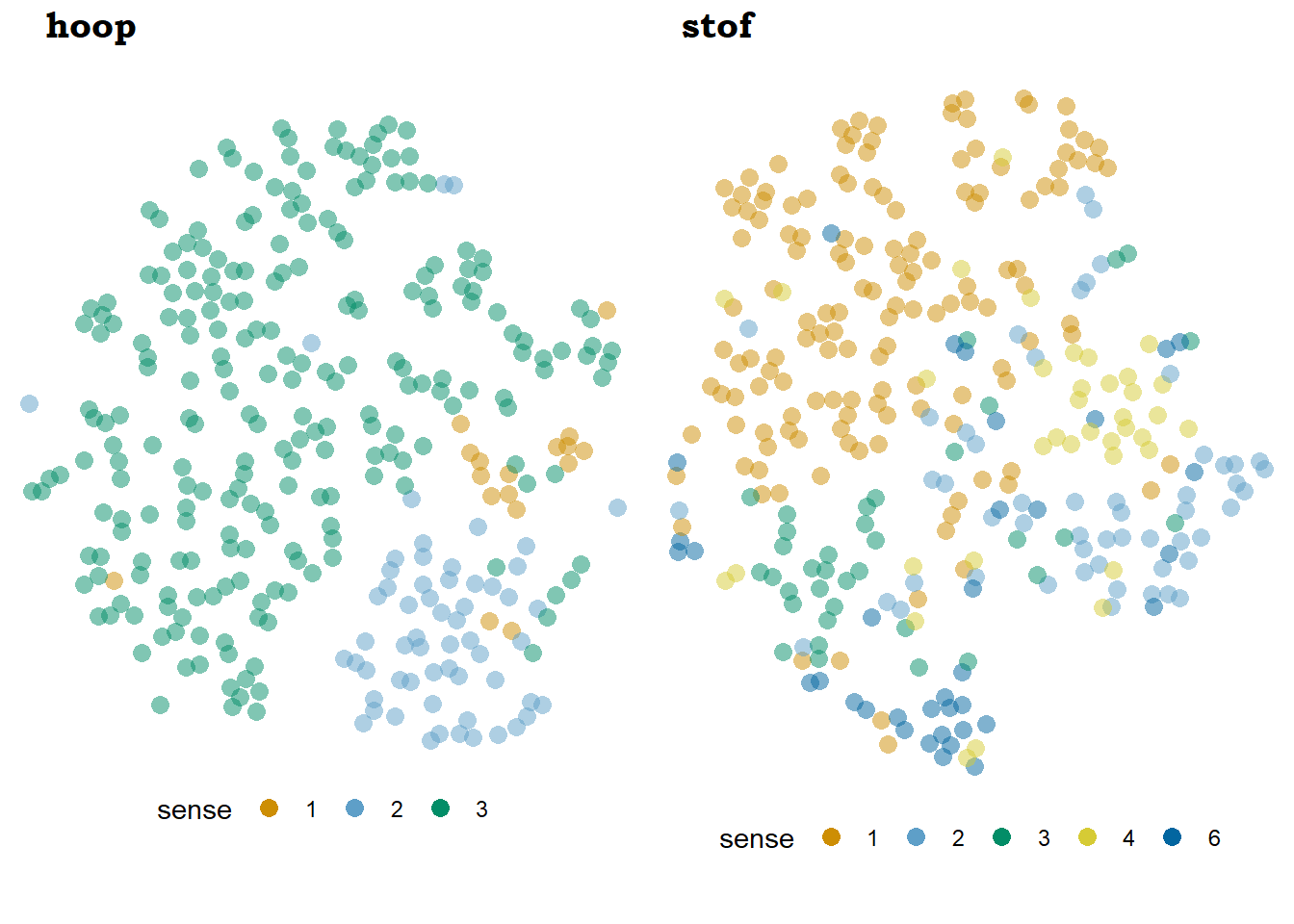
Figure 7.1: Best medoids of hoop (pathweight-ppmino-focall) and stof (bound5lex-ppmiselection-focall).
The senses plotted to the colours are coded with numbers to avoid cluttering. The senses of hoop are, for the first homonym, [1] literal ‘heap, pile’ and [2] general ‘heap, bunch,’ and for the second homonym, [3] ‘hope.’ The first homonym of stof includes [1] ‘substance,’ [2] ‘fabric’ and [3] ‘topic, material,’ while the second covers [4] literal ‘dust’ and [6] idiomatic ‘dust.’ There is no sense [5], originally ‘(reduced to) dust,’ because it was not attested. Some relevant examples will be given below.
The parameters that result in these models are in fact very different, although their second-order configuration is equivalent: the union of all the context words captured by the model are also used as second-order dimensions. As a result, the dimensionality of the token-level vectors is quite low: 833 for hoop and 483 for stof.
The model that works best for hoop is the only medoid that manages to group the tokens of the ‘heap’ homonym away from the larger mass of ‘hoop’ tokens (in green), with even a neat moat in between. If we sacrifice the infrequent literal ‘heap’ sense (in orange), the split is indeed outstanding. This is achieved by a PATHweight model: it uses syntactic information, selects the context words connected up to three steps away from the target, and weights the contribution of each item on that distance, regardless of the precise nature of the syntactic relationship, part-of-speech information or pmi. The syntactic distances, i.e. the number of steps to the target in the dependency path, are illustrated with the superscripts in examples (47) and (48).
In (47), the indefinite determiner een and the modified noun onzin ‘nonsense’ are directly linked to the target hoop as dependent and head respectively, so they are taken by the model and receive the highest weight. The first occurrence of the verb is is the head of its subject onzin ‘nonsense,’ hence two steps away of the target: it is included and receives a slightly lower weight. The particle er, which is tagged as a modifier of is, and the second instance of is, as head of the subordinate clause, are three steps away from the target, and therefore obtain a low weight. The rest of the context is ignored by this model.
Example (48) offers a much more complex picture, particularly because the link between the target hoop ‘hope’ and the verb spreek_uit ‘to express’ (split in sprak and its particle uit), is short. As the core of the dependency tree, the main verb opens the path to many other elements in the sentence.
-
Er3 is2 een1hoop onzin1, talent is3 niet iedereen gegeven. (Algemeen Dagblad, 2001-01-27, Art. 78)
‘There is a lot of nonsense; talent is not given to everyone.’
-
De3 trainer2 van3 FC Utrecht sprak1 verder2 de1hoop uit2 dat1 hij3 binnenkort weer eens mag2 investeren3 van de clubleiding. (NRC Handelsblad, 2004-05-24, Art. 93)
‘The manager of FC Utrecht also expressed the hope that the club management would allow him to invest once again soon.’
A key point for this lemma is that hoop ‘hope,’ represented by (48), is a mass noun, and therefore tends to occur with the definite determiner de (40% of the cases). In contrast, hoop ‘heap,’ represented by (47), tends to occur with een ‘a(n)’ (64 out of 76 occurrences). This correlation is hard to extract with a bag-of-words model, which would either filter out function words such as the determiners, or include all determiners, related to the target or not, thus drowning this pattern in noise.
In contrast, the parameter settings that work best for stof are bound5lex and PPMIselection, i.e. they capture the nouns, verbs, adjectives and adverbs within 5 slots to each side of the target, as long as they are within the limits of the sentence and their pmi with the target lemma is positive. In the case of (49), for example, the model selects discussie ‘discussion’ and lever_op ‘to bring about, to return,’ in italics in the transcription. Words that might follow after the period would be excluded by this model, as are those before film ‘movie.’ Within the window span of 5 words to each side, die ‘that,’ na ‘after,’ veel ‘much’ and tot ‘to’ are excluded because of the part-of-speech filter. Finally, the nouns film ‘movie’ and afloop ‘end, conclusion,’ which survive the window size and part-of-speech filters, are excluded by the association strength filter, since their pmi value in relation to stof is lower than 0.
-
Dit is een perfect voorbeeld van een film die na afloop veel stof tot discussie oplevert. (Algemeen Dagblad, 2003-12-11, Art. 58)
‘This is a perfect example of a film that afterwards provides a lot of food for thought (lit. `stuff for discussion’).’
Being generous, we can find a good representation of granularity of meaning for hoop in Figure 7.1. In the case of stof, however, the senses are quite well distinguished but the homonyms are not. First, most of the idiomatic ‘dust’ tokens group quite nicely in some sort of appendix to the main cloud. These tokens, which are by definition idiomatic uses of stof, tend to be very tightly grouped in most models. An example can be seen in (50). Notably, they also include a few literal tokens that also co-occur with one of the defining context words, i.e. doe ‘to make’ and waai_op ‘to lift.’
-
Het huwelijk tussen de hervormde Maurits en de katholieke Marylene deed de nodige stof opwaaien. (Algemeen Dagblad, 1999-12-08, Art. 3)
‘The wedding between Maurit, a Reformed Christian, and Marylene, a Catholic, inspired a much needed debate (lit. `stirred up the necessary dust’).’
The rest of the tokens seem to be organized by sense with subtle borders in between. The most frequent sense, ‘substance,’ even includes a few independent islands on top, already discussed in Section 6.2.4.
Most interestingly, ‘fabric’ and ‘dust,’ in light blue and yellow respectively, like to go together, even though they belong to different homonyms. In fact, hdbscan merges them together in one cluster, as we will see in Figure 7.3. This is not entirely surprising, given that both senses tend to co-occur with quite concrete context words, such as names for materials and colours (see for example (51) and (52)), while the ‘substance’ sense is more chemically-oriented and the ‘topic, material’ sense, illustrated in (49), co-occurs with the semantic domain of communication instead.
-
Dankzij de nieuwe vlekwerende ``stay clean"-behandelingen dringen zelfs vloeistoffen zoals olie, vruchtensap of water niet in de stof. (De Standaard, 2001-01-19, Art. 6)
‘Thanks to the new stain-resistant ``stay clean" treatments even liquids such as oil, fruit juice or water do not penetrate the fabric.’
-
Na het stof de douche. De tocht door de Hel zit er op. (De Morgen, 2003-04-15, Art. 65)
‘After the dust the shower. The trip through Hell [a cobblestone cycling road] is over.’
This description should suffice to understand how very different parameter configurations are necessary to model such different lemmas. The fact that both of them are homonyms is not enough: other aspects of their structure, such as the kind of contextual features that characterize each sense or homonym, play a role.
What I have not shown is that other models are not as good. What would come out from applying the parameter settings that work best for one lemma onto the other? This we see in Figure 7.2.
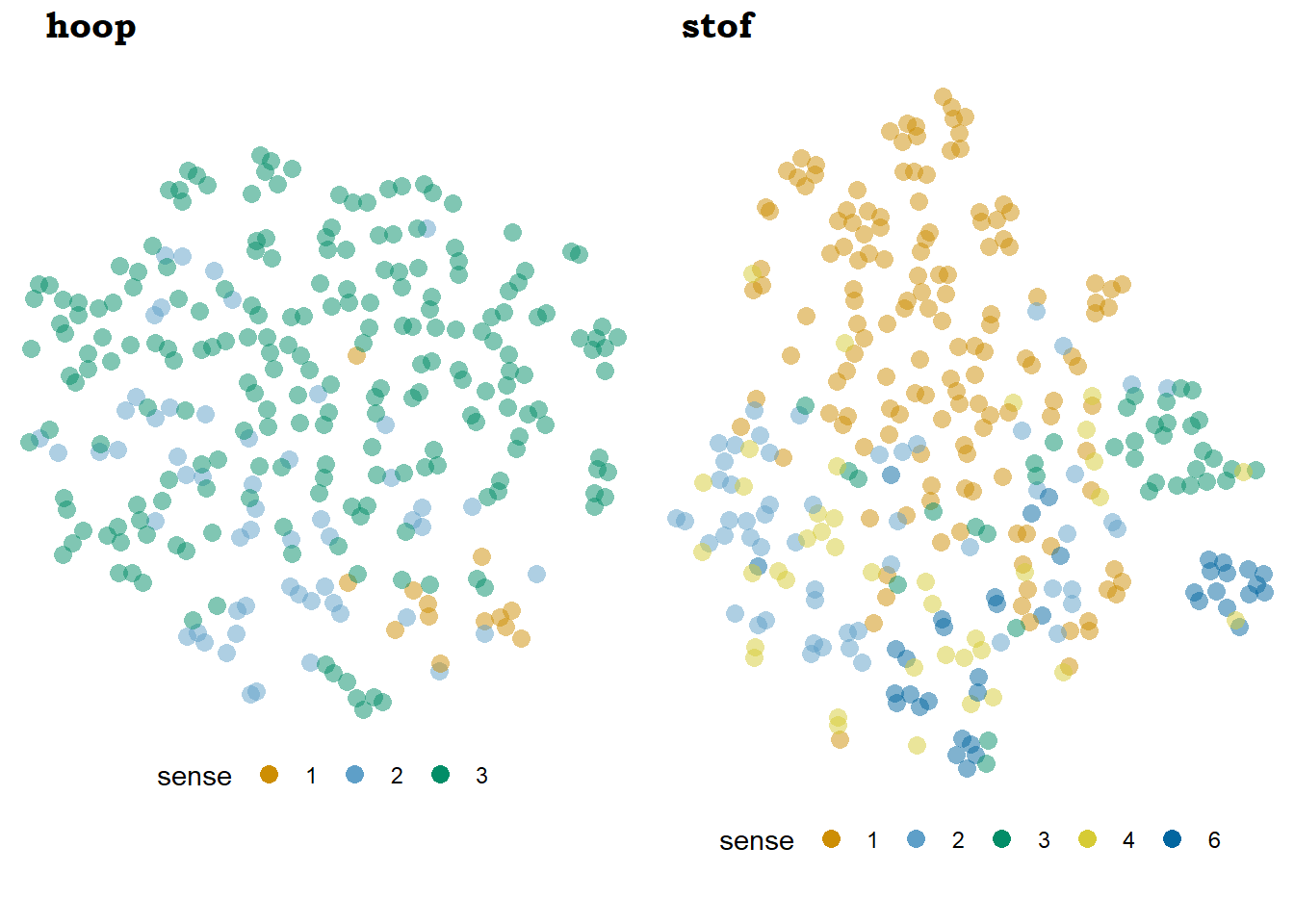
Figure 7.2: Model of hoop with the parameters that work best for stof and viceversa: bound5lex-ppmiselection-focall for hoop and pathweight-ppmino-focallfor stof
Indeed, swapping the configurations returns unsatisfying results. In the case of hoop, we see a similar picture to many other models: a plot overrun by ‘hope,’ with maybe an area with more ‘literal heap’ tokens, while the ‘general heap’ tokens, that were so nicely separated in Figure 7.1, are mixed and distributed across one hemisphere. In the case of stof, we keep having a large ‘substance’ area in orange, an isolated blue section for the idiomatic ‘dust’ and a shy green peninsula of ‘topic, material’ tokens, but the concrete senses, ‘fabric’ and ‘dust,’ are disperse and mixed.
Even for a fairly straightforward task as discriminating homonyms, parameters that succeed in one lemma fail in the other. This is unrelated to the number or frequency of the senses. Instead, it is inextricably linked to the particular distributional behaviour of each lemma. While stof can find collocations or semantic preferences that, to various degrees, represent (parts of) senses, the lexical contexts of hoop are too varied to generate clear clusters. On the other hand, a syntactically informed model can identify determiners as a relevant feature of hoop, while the same information seems less interesting in regard to stof.
|
Only lex
|
lex or PPMIweight
|
No lex effect
|
||||
|---|---|---|---|---|---|---|
| SOC effect | radial window | no window | radial window | no window | radial window | no window |
| 5000-all | horde, gekleurd, hoopvol, haten, helpen | staal, blik, hemels, gemeen, grijs | stof, dof, geestig, heet | hoekig, geldig, goedkoop | ||
| 5000 around | hachelijk | haken | spot, schaal | heilzaam | heffen\(^1\) | |
| None | hoop, herinneren, herstellen\(^1\), harden\(^1\) | herhalen, diskwalificeren, herstructureren | huldigen\(^2\) | herroepen | ||
| 1 Models with window size of 3 are separated, no radial structure. | ||||||
| 2 Dependency-based models are closer to those with larger window instead of those with smaller window. | ||||||
7.2 Weather forecast gone crazy
Parameter settings do not have an equal effect across all models. Even at Level 1, where we compare models of a lemma with each other, we encounter a variety of patterns.
Table 7.1 groups all the lemmas based on the three criteria that make the greatest difference in the organization of the Level 1 plots. The main columns refer to effects of the first-order part-of-speech filter and the ppmi weighting: in the first group of lemmas, lex models occupy a specific area of the Level 1 plot; in the second they are isolated next to the PPMIweight models (and sometimes REL as well), and in the third, no effect of the part-of-speech setting is found. The next level of columns distinguishes the effect of window size among the BOW models. A radial window configuration means that models with a window of 5 lie between those with a window of 3 and those with a window of 10. Typically, the models with smaller windows are closer to the dependency-based models, with huldigen being an exception. Three of these lemmas do not really exhibit a radial structure, but the models with the smallest window tend to be isolated instead. Finally, the rows indicate an effect of the second-order vectors: the first row gathers the lemmas with a separate section for the 5000all second-order configuration; the second, lemmas where models with 5000 vectors simply have a tendency to wrap around the rest of the models (like the wings of a beetle), and the third row is used for the lemmas where second-order parameters have no special effect on the organization of their models. Models with 5000all second-order configuration are consistently messy, and tend to make the type-level distances between all pairs of context words huge.
As we can see in the table, these patterns are not related to the part-of-speech of the target or the semantic phenomena we expect in it. This variability and the different ranges of distances between the models are the reason why selecting medoids is the most reasonable way of exploring the diversity of models.
Qualitatively, the same set of parameter settings can generate multiple different solutions, depending on the distributional properties of the lemma being modelled. We already saw this in the comparison between Figures 7.1 and 7.2: what works best for one lemma will not necessary give a decent result in another. In this section, we briefly look at the models previously plotted in Figures 5.1 and 5.2. In all cases, the parameter settings are the same of the best model of stof: bound5lex-ppmiselection-focall. The colour-coding matches the hdbscan clusters, and the shapes, the annotated senses.
In Figure 7.3, we see the same model for heet ‘hot’ and stof ‘substance, dust….’ The model of heet ‘hot’ has 12 clusters, with roughly equal proportion of Cumulus, Stratocumulus and Cirrus clouds. Most of them are collocation clusters representing typical patterns within a sense, but we also find cases of semantic preference and a few heterogeneous near-open choice clusters. The stof ‘substance, dust…’ model looks roughly similar, with 7 relatively homogeneous clusters: the three Stratocumulus on the upper left are the collocation clusters discussed in Section 6.2.4 and, next to the red Cirrus defined by semantic preference, they represent typical uses of the ‘substance’ sense. The rest of the clusters, as discussed above, are more heterogeneous. A further difference between the two lemmas is that, while the homogeneous clouds of stof ‘substance’ represent typical uses that profile different dimensions of the sense, the typical patterns within heet ‘hot’ constitute idiomatic expressions.
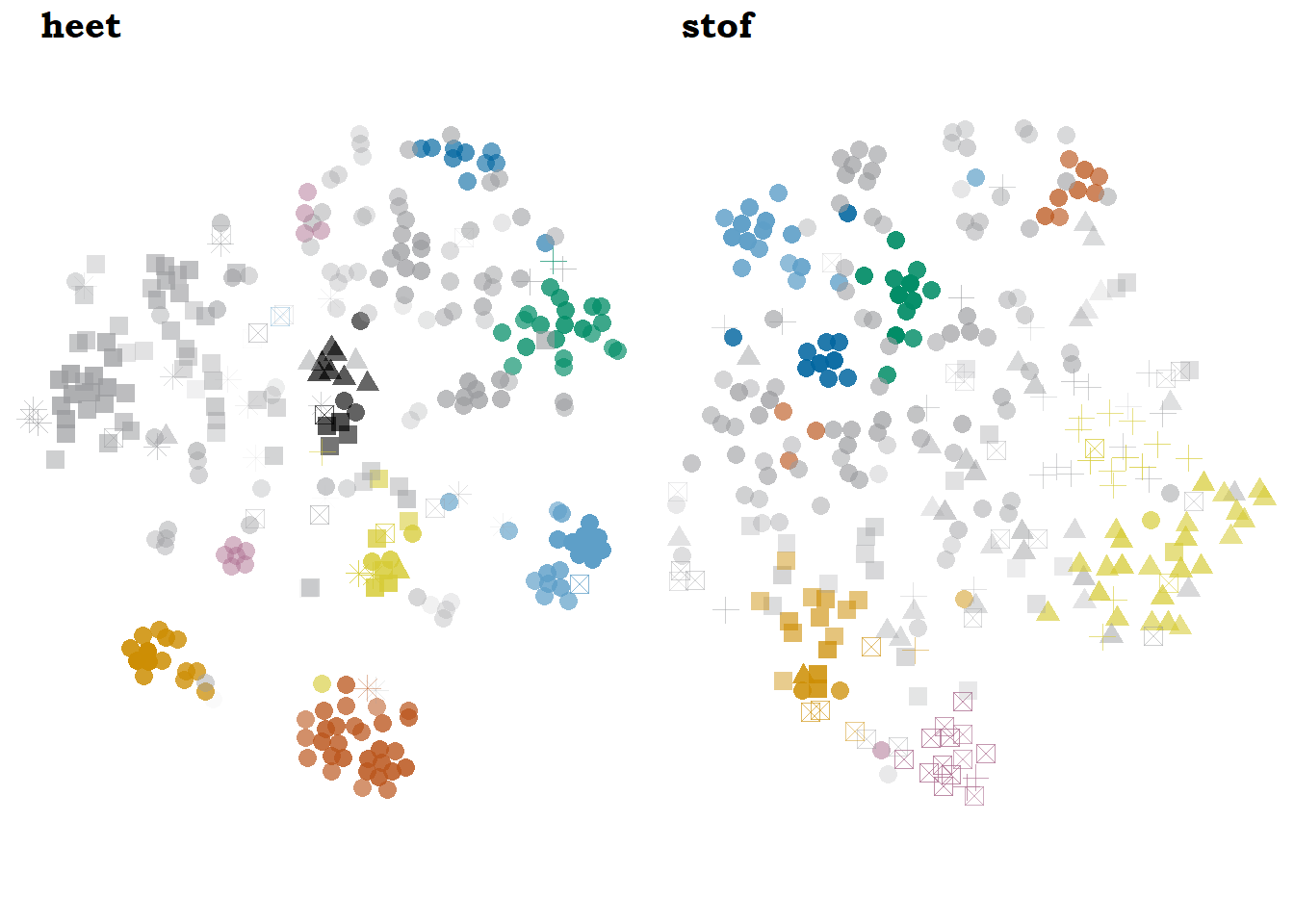
Figure 7.3: Models of heet and stof with bound5lex-ppmiselection-focall.
The lemmas shown in Figure 7.4, dof ‘dull’ and huldigen ‘to believe/to honour,’ look rather similar to each other but very different from the ones in Figure 7.3. Even though dof ‘dull,’ not unlike heet, tends to have multiple clusters characterized by collocations with different types of sounds, it takes a different shape in this model. The metaphorical sense represented by the collocation with ellende ‘misery’ forms a neat orange Cumulus on one side; the semantic preference for sounds gives rise to the homogeneous light blue Stratocumulus below, and the rest of the tokens, both those related to the visual sense and the rest of the metaphorical ones, gather in the heterogeneous green Stratocumulus. As we have seen before, huldigen also has some strong collocates, but in this model, the tokens of ‘to believe,’ led by principe ‘principle,’ opvatting ‘opinion’ and standpunt ‘point of view,’ take part of an extremely homogeneous orange Stratocumulus, while most of the ‘to pay homage’ sense covers the light blue Cumulonimbus, like in the case described in Section 6.5.2.
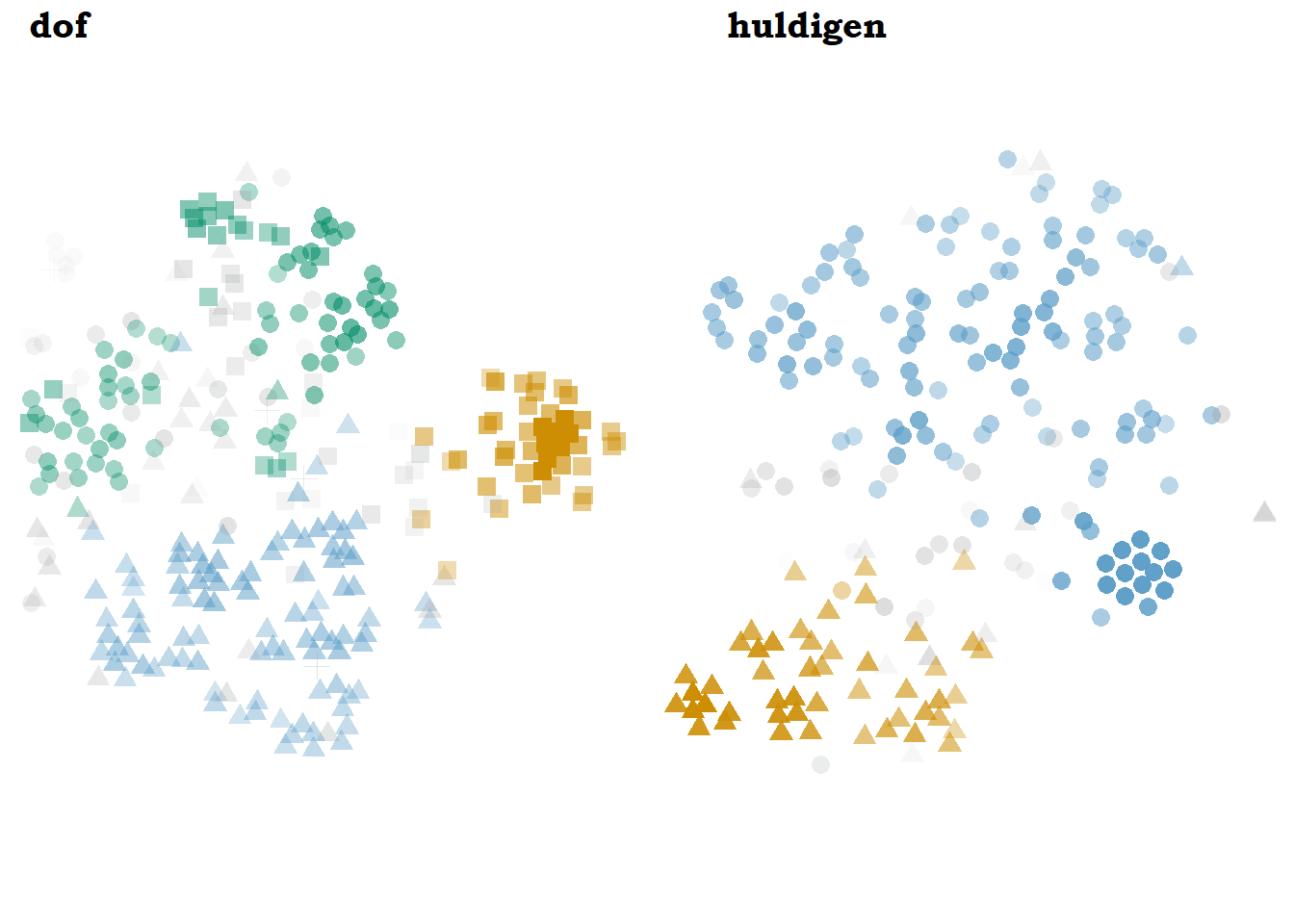
Figure 7.4: Models of dof and huldigen with bound5lex-ppmiselection-focall.
The lemmas in Figure 7.5, haten ‘to hate’ and hoop ‘hope/heap,’ show yet another configuration generated by the same parameter settings. Except for the green Stratocumulus in haten, roughly dominated by mens ‘human, people,’ the rest of the clouds are Cirrus clouds: small, heterogeneous, characterized by many different words.
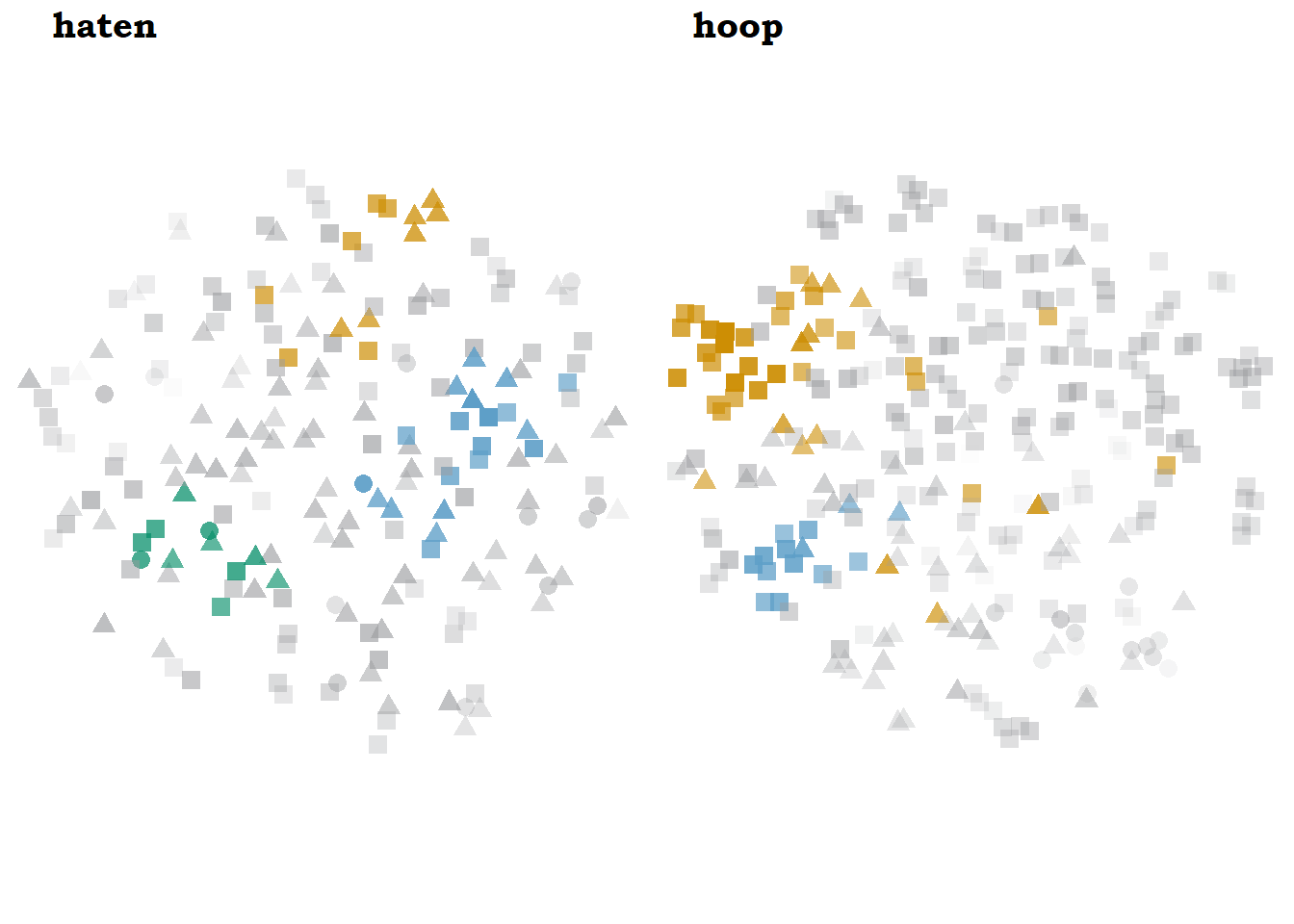
Figure 7.5: Models of haten and hoop with bound5lex-ppmiselection-focall.
7.3 Summary
The output of a model is not directly predictable from its parameter settings. Clouds can take many shapes, lemmas exhibit different distributional patterns, and these patterns can have different semantic interpretations. The parameter settings that model one phenomenon best, in a certain model, will not necessarily model the same phenomenon in another lemma, or anything else of interest for that matter. The same parameter settings can result in drastically different shapes across lemmas, or even if the shapes are similar and they are the result of comparable distributional behaviours, they might have different semantic interpretations.
With these cheerful thoughts, the analytical part of this dissertation comes to an end. In the next chapter I will conclude with a brief summary of the findings in the form of guidelines — tips and tricks for the interested cloudspotter — thoughts for further research.