6 The language of clouds
In linguistic terms, clouds may provide us with different types of information, both at syntagmatic and paradigmatic level. At the syntagmatic level, they may illustrate cases of collocation, colligation, semantic preference or even tendencies towards the open-choice principle. The paradigmatic level, on the other hand, codes the relationship between the clusters and dictionary senses, from heterogeneous clusters to those that represent (proto)typical contexts of a sense.
Given a naive understanding of the correlation between context and meaning, we would mostly expect, from the paradigmatic perspective, clusters that equal senses: each cloud would cover all the occurrences of a dictionary sense and only the occurrences of that sense. However, even if we relax the requirements, expecting mostly homogeneous clusters covering most of the clustered tokens, this does not arise often. Instead, even homogeneous clusters only group typical contexts within a sense, which, at the syntagmatic level, tend to correspond to collocations. In any case, as we will see in this chapter, the full picture is more complex, and we can obtain much richer information than just lexical collocations representing typical contexts within a sense.
In this chapter, we will look into the types of syntagmatic and paradigmatic information that the clouds offer. Section 6.1 starts with an overview of the different levels in each dimension and mentions a few examples of their interaction in a contingency table. We then elaborate with more detailed examples of each in situation in sections 6.2 through 6.5, and round up with an overall summary in Section 6.6.
6.1 Types of information
The linguistic information obtainable from the clusters can be understood from the syntagmatic perspective as co-occurrence patterns of different kinds, and from the paradigmatic perspective in relation to dictionary senses. Both dimensions interlace, resulting in a number of specific phenomena that we may encounter. The relationship is summarized in Table 6.1; the syntagmatic or collocational dimension is represented by the columns and discussed in Section 6.1.1, and the paradigmatic or semantic dimension is represented by the rows and discussed in Section 6.1.2.
6.1.1 Collocational perspective
In order to interpret the different levels of information that a syntagmatic or collocational perspective may offer us, we can make use of some theoretical concepts from the foundations of Corpus Linguistics. Some of the terms were already coined by Firth (1957), but they were integrated in a framework for corpus analysis by Sinclair (1998: 124–125) and other publications. The framework includes, next to the node, i.e. our targets, four key components: one obligatory — semantic prosody, which will not be discussed here — and three more that will help us make sense of the observed output of the clouds: collocation, colligation and semantic preference.
In their simplest form, collocations are defined as the co-occurrence of two words within a certain span (Firth 1957: 13; Sinclair 1991: 170; Sinclair 1998: 15; Stubbs 2009: 124). They might be further filtered by the statistical significance of their co-occurrence frequency or by their strength of attraction; such as pmi (see McEnery & Hardie 2012: 122–133 for a discussion). Even though a collocational relationship is asymmetric, that is, the co-occurrence with a more frequent word B may be more important for the less frequent word A than for B, the measures used to described it are most often symmetrical (Gries 2013). When it comes to the interpretation of clouds, this category takes a different form and is definitely asymmetric. Considering models built around a target term or node, frequent, distinct context words are bound to make the tokens that co-occur with them similar to each other and different from the rest: they will generate clusters. Such context words do tend to have a high pmi with the target, but, crucially, they stand out because they are a salient feature among the occurrences of the target, independently from how salient the target would be when modelling the collocate. Concretely, we are talking about clusters defined by one context word or a group of co-occurring context words with a high \(F\)-score in relation to the cluster: these context words can be interpreted as collocates of the target. Unlike in most collocational studies, where you study a list of words that co-occur (significantly) frequently with your target node, vector space models allow you to see whether these context words exclude each other or also co-occur within the context of the target. In fact, we might even find more complex collocational patterns, including multiple context words.
Whereas collocation is understood as a relationship between words (and, traditionally, as a relationship between word forms), colligation is defined as a relationship between a word and grammatical categories or syntactic patterns (Firth 1957: 14; Sinclair 1998: 15; Stubbs 2009: 124). In order to capture proper colligations as clusters, we would need models in which parts of speech or maybe dependency patterns are used as features, which is not the case in these studies. However, by rejecting a strict separation between syntax and lexis (for everything is semantics in Cognitive Linguistics), we can make a grammatically-oriented interpretation of collocations with function words, such as frequent prepositions or the passive auxiliary. Given this caveat, we will talk about lexically instantiated colligations when we encounter clusters dominated by items that indicate a specific grammatical function.
Semantic preference is defined as the relationship between a word and semantically similar words (Sinclair 1998: 16; Stubbs 2009: 125; McEnery & Hardie 2012: 138–140). Within traditional collocational studies, this implies grouping collocates, that is, already frequently co-occurring items, based on semantic similarity, much as colligation can be the result of grouping collocates based on their grammatical categories. Compared to collocation, its identification requires more interpretation on the part of the researcher. In the interpretation of individual clusters, semantic preference appears in clusters that are not dominated by a single collocate or group of co-occurring collocates, but are instead defined by a group of infrequent context words with similar type-level vectors and for which we can give a semantic interpretation. (Cases of similar context words without a semantic interpretation are quite rare, and normally involve pronouns or adverbs.) This is a key contribution of token-level distributional models that may remain inaccessible in traditional collocational studies: next to powerful collocates that group virtually identical occurrences, we can identify patterns in which the context words are not the exact same but are similar enough to emulate a collocate.
The three notions described above assume identifiable patterns: occurrences that are similar enough to a substantial number of other occurrences, and different enough from other occurrences, to generate a cluster. Going back to Sinclair (1991)’s founding notions, we are assuming the domination of the idiom principle:
…a language user has available to him or her a large number of semi-preconstructed phrases that constitute single choices, even though they might appear to be analysable into segments. (Sinclair 1991: 110)
The opposite situation would be given by the open-choice principle:
At each point where a unit is completed (a word or a phrase or a clause), a large range of choice opens up and the only restraint is grammaticalness. (Sinclair 1991: 109)
The idiom principle and the open-choice principle are supposed to organise the lexicon and the production of utterances. But if, instead, they are understood as poles in the continuum of collocational behaviour, they can help us interpret the variety of shapes that we encounter within and across lemmas. Lemmas in which we tend to find identifiable clusters, with strong collocations, lexically instantiated colligations or sets with semantic preference, can be said to respond to the idiom principle. In contrast, lemmas that exhibit large proportions of noise tokens, and small, diffuse clusters (Cirrus clouds, mostly), can be said to approximate the open-choice principle. They don’t necessarily lack structure, but whatever structure they have is less clear than for other lemmas, and harder to capture with these models. With this reasoning, next to the three categories described above, we include near-open choice as a fourth category, meant to include the clouds that do not conform to either of the clearer formats.
6.1.2 Semantic perspective
In terms of the relationship between the hdbscan clusters and the manually annotated dictionary senses, we can initially distinguish between heterogeneous clusters, i.e. those that do not exhibit a clear preference for one sense, and homogeneous clusters. Secondly, the homogeneous clusters may cover all the (clustered) tokens of a given sense, or only part of it, i.e. a (proto)typical context of the sense. Additionally, said (proto)typical context may highlight a certain aspect or dimension of the meaning of the target, different from that highlighted by a different context.
As a result, the semantic dimension covers four different types of situations. The first one, i.e. heterogeneous clusters or clusters with multiple senses, would normally be interpreted as bad modelling, if we consider the senses a gold standard and the target of our models. It is also the most frequent interpretation of the near-open choice clouds. Nonetheless, they can also occur in other kinds of clouds, and as such illustrate the mismatch between contextual and semantic structure: clear contextual patterns do not imply dictionary senses. The second type of situation, i.e. clusters that perfectly match senses, is the ideal situation and what we would initially expect from distributional models. Instead, it is quite rare and often indicative of fixed expressions or very particular meanings. Rather than full senses, contextual patterns tend to represent (proto)typical contexts of a sense.
As it was already described in Section 1.2.2, the notion of prototypicality in Cognitive Semantics is related to the principle that categories need not be discrete and uniform and to its application to the semasiological structure of lemmas and their meanings (Geeraerts 1988; Geeraerts 1997). At the extensional level, which in this case covers the domains or contexts of application of our target item, categories may be defined by a varied set of overlapping features (i.e. context words) and have fuzzy boundaries and/or degrees of membership. The central or more prototypical members of this category exhibit more of these overlapping features; the fewer features co-occur with an item, the weaker its connection to the category. As they appear in the clouds, a sense may exhibit one typical context that is much more frequent and clear that the rest, or multiple typical contexts with similar frequencies. Unfortunately, neither t-sne nor hdbscan provide a reliable mapping between quantitative properties and relative centrality of the clusters. In contrast, we can identify central cases within an hdbscan cluster based on their membership probability, which, as briefly mentioned before, is the normalized core distance within a cluster. Items with a higher membership probability lie in a denser area of an hdbscan cluster, and therefore have more items similar to it than the items in sparser areas. They do not necessarily occur in the euclidean centre in the t-sne plot, but might form one or more dense cores closer towards an edge instead. In addition, we can distinguish between rather uniform clusters, in which all members have a similar weight, from more diverse clusters with dense cores and sparse peripheries.
Extensional prototypicality works at multiple levels. We could identify (proto)typical instances/contexts of a lemma, of a particular sense, or of a dimension of a sense. In this last case, we run into an interaction with intensional prototypicality. On the one hand, we find multiple extensionally prototypical patterns, i.e. two or more groups of attestations that instantiate different patterns. On the other, each of these patterns correlates with a different semantic dimension or aspect, wich means that that meaning dimension is salient (intensional prototypicality) to that pattern.
6.1.3 Interaction between dimensions
As we can see in Table 6.1, the interaction between the four levels of each dimension result in a 4x4 table with all but two cells filled with at least one example. Naturally, not all the combinations are equally frequent or interesting; the most salient one is certainly the collocation that indicates the prototypical context of a sense. But this does not mean that the rest of the phenomena should be ignored: we can still find interesting and useful information with other shapes of clouds, other contextual patterns, other semantic structure.
In the following sections, we will look in detail at examples of each attested combination. Each section will focus on one level of the collocational dimension, and will be further subdivided by the levels of the semantic dimension. The examples will be illustrated with scatterplots in which the colours represent hdbscan clusters, the shapes indicate manually annotated dictionary senses, and the transparency, the \(\varepsilon\) value from hdbscan. The senses are not specified in the legends, but the clusters will be named with the context word that represents it best (see Section 5.2). Textual reproductions of some tokens will also be offered; in all cases the target will be in bold face and the context words captured by the relevant model, in italics. The name of the newspaper, the date of publication and the number of the article will follow the original text, and the following paragraph will reproduce the English translation between simple inverted commas.
| Semantic interpretation | Single collocation | Lexically instantiated colligation | Semantic preference | Near-open choice |
|---|---|---|---|---|
| Heterogeneous clusters | heilzaam ‘healthy/beneficial’ + werking ‘effect’ (and relatives) | herstructureren ‘to restructure’ + passive aux. word (part of the two transitive senses); helpen ‘to help’ + om & te ‘in order to’ | geestig ‘witty’ + wijze/manier ‘manner’/various adverbs; grijs ‘grey’ + colours and clothes; herroepen ‘to recant/to void’ + uitspraak ‘statement/verdict’ & juridical field | blik ‘gaze/tin’ - werpen ‘to throw,’ richten ‘to aim’ |
| Dictionary clusters | staal ‘sample’ + representatief ‘representative’; schaal ‘dish of a scale’ + gewicht ‘weight’; schaal ‘scale’ + Richter | herhalen ‘to repeat’ + zich ‘itself’; hoop ‘hope/heap,’ in the one model that gets the senses right | haken ‘to make trip/to crochet’ + sports terms or hobby terms; schaal ‘scale’ + earthquake-topic or kitchen-topic | huldigen ‘to honour’ |
| (Proto)typical context | heffen ‘to levy/to lift’ and all its collocates (except for hand/arm); hachelijk ‘dangerous/critical’ and its collocates | diskwalificeren ‘to disqualify’ + passive aux. word; helpen ‘to help’ + different pronouns/prepositions (bij, aan) as only remaining context words; herinneren ‘to remember/to remind’ + (er)aan ‘of (it),’ ik ‘I’ & reflexive pron. me, zich | grijs ‘grey’ + cars; heet ‘hot’ + food; hemels ‘heavenly’ + music; dof ‘dull’ + sounds | -Not relevant- |
| (Proto)typical context with profiling | stof ‘substance’ and its adjectives; horde ‘horde’ | horde ‘horde’ + journalist & door ‘by’ | geldig ‘valid’ + tickets & dates / identity documents & voorleggen ‘submit’ /bezitten ‘possess’; staal ‘steel’ + ton & milioen ‘million’ / materials | -Not relevant- |
6.2 Collocation
The first level of the collocational or syntagmatic dimension is that of the collocation: clusters dominated by one context word or a group of co-occurring context words. They are most likely to be found as Cumulus clouds, but also as Stratocumulus clouds or, very rarely, Cirrus clouds.
6.2.1 Heterogeneous clouds
Albeit infrequently, collocations might transcend senses, that is, they might be frequent and even distinctive of a lemma without showing a preference for a specific sense. The most clear example is found in heilzaam ‘healthy/beneficial,’ which can mean that something is literally beneficial for the health or be applied, metaphorically, to other domains as well. Its clusters tend to be dominated by one context word that is not indicative of any one sense: mostly werking ‘effect’ and effect, adding in some models the less frequent invloed ‘influence.’ Some examples of are shown in (5) and (6) for the ‘healthy’ sense and (7) and (8) for the ‘beneficial’ sense.
-
Het lypoceen, een bestanddeel dat bijdraagt aan de rode kleur, zou een heilzame werking hebben op de prostaat. (De Volkskrant, 2003-11-08, Art. 14)
‘Lypocene, a component that contributes to the red colour, would have a healing power on the prostate.’
-
Pierik beschrijft de heilzame effecten van alcoholgebruik op de bloedvaten en de bloeddruk, op mogelijke beroerten, galstenen, lichaamsgewicht, vruchtbaarheid, zwangerschap, botontkalking, kanker, verkoudheid, suikerziekte en seniele dementie. (NRC Handelsblad, 1999-11-27, Art. 148)
‘Pierik describes the healing powers of alcohol consumption on [the] blood vessels and [the] blood pressure, on potential strokes, gallstones, body weight, fertility, pregnancy, osteoporosis, cancer, the cold, diabetes and senile dementia.’
-
Voor politici met dadendrang een gruwel, maar als men de casus van de Betuwelijn nog voor de geest haalt dan zou het advocatensysteem zijn heilzame werking hebben kunnen bewijzen. (De Volkskrant, 2002-03-29, Art. 79)
‘For politicians with thirst for action it is an abomination, but when one recalls (lit. `brings to the spirit’) the case of the Betuwe line then the lawyer system would have been able to prove its beneficial effect.’
-
De kwestie heeft alvast één heilzaam effect: het profiel van commerciële boekenprijzen staat opnieuw ter discussie. (De Standaard, 1999-03-27, Art. 133)
‘The matter certainly has a beneficial effect: the profile of commercial book prizes is again under discussion.’
The model is shown in Figure 6.1: the clusters dominated by werking ‘effect,’ effect and invloed ‘influence’ are shown in yellow, light blue and green, respectively, and the manually annotated senses are mapped to the shapes: the literal ‘healthy’ sense is coded in circles, and the general sense, in triangles. All but the invloed ‘invloed’ cluster, a Cumulus, are Stratocumulus clouds.
Within the werking ‘effect’ cluster, the literal tokens (as in (5)) are the majority and tend towards the left side of the cloud, whereas the general ones (like (7)) tend towards the right side. While there is a preference for the literal sense, especially considering that across the full sample the general sense is more frequent, it is far from homogeneous. The balance is even more striking within the effect cluster. Such a picture is pervasive across multiple models of heilzaam ‘healthy/beneficial.’ The vague organization within the werking ‘effect’ cluster suggests that it is not necessarily the case that the models do not capture words representative of ‘physical health,’ but they have to compete with the most salient context words, which are not precisely discriminative of these two senses.
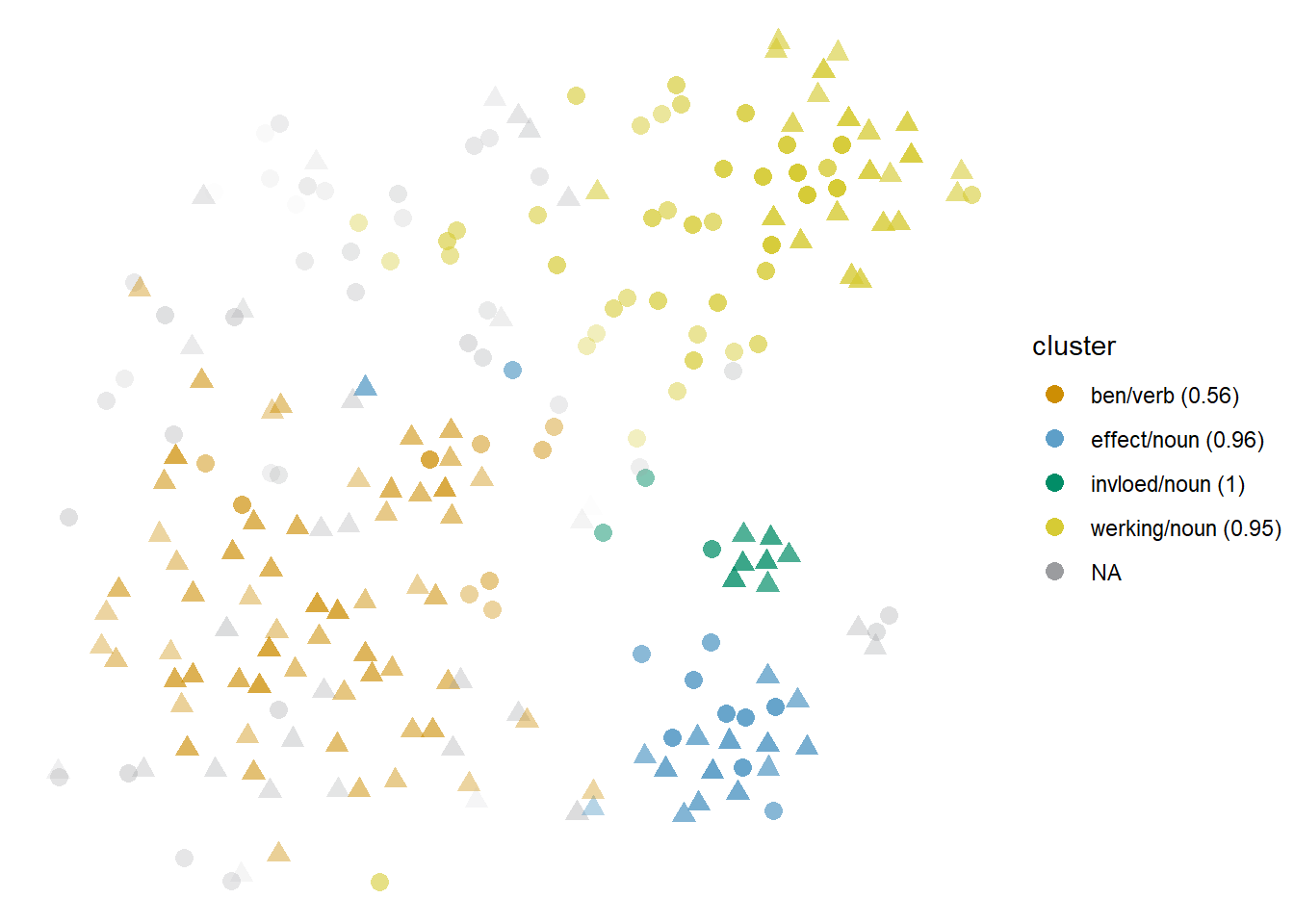
Figure 6.1: Cloud of heilzaam: bound10all-ppmiweight-focall. Circles are ‘healthy, healing,’ triangles are ‘beneficial’ in general.
This is an issue if we come to the distributional semantics expecting lexical collocates, such as werking ‘werking,’ effect, and invloed ‘influence,’ to unequivocally represent different dictionary senses. On the other hand, ben ‘to be’ and werk ‘to work, to have an effect’ (of which werking is a nominalization), co-occur with the tokens in the orange cluster, dominated by the general sense, and less so outside this cluster; see examples (9) and (10). In other words, the most frequent nouns modified by heilzaam ‘beneficial’ tend to occur in attributive constructions (particularly een heilzame werking hebben ‘to have a beneficial/healing effect/power’ and de heilzame werking van ‘the beneficial/healing effect/power of’) and for either sense, whereas the predicative constructions present a wider variety of nouns and a stronger tendency towards the general sense.
-
Versterking van de politieke controle op de Commissie kan heilzaam zijn maar de huidige ongenuanceerde discussie is gevaarlijk voor Europees beleid en besluitvorming. (De Morgen, 1999-03-18, Art. 45)
‘Reinforcement of the politicial control at the Commission can be beneficial, but the current unnuanced discussion is dangerous for European policy and decision-making.’
-
Ten slotte nog één fundamentele bedenking: ook de permanente actualiteit van de thematiek in de media werkt heilzaam op de weggebruikers. (De Morgen, 2001-02-28, Art. 107)
‘To conclude, one final fundamental thought: the permanent presence of the topic in the media has a beneficial effect (lit. `works beneficially’) on road users.’
The models of heilzaam ‘healthy/beneficial’ show that that we cannot take for granted that collocations will be representative of senses. What is more, they illustrate how neither a high pmi nor their selection as cues by human annotators guarantee that a context word distinguishes predefined senses, given that these words have both a high pmi with heilzaam ‘healthy/beneficial’ and were often selected as cues by the annotators (recall Tables 4.5 and 4.6 in Chapter 4) . When it comes to pmi, it is understandable: the measure is meant to indicate how distinctive a context word is of the type as a whole, in comparison to other types. It does not take into account how distinctive it is of a group of occurrences against another group of occurrences of the same type. When it comes to cueness annotation, however, we could have expected a more reliable selection, but apparently the salience of these context words is too high for the annotators to notice that it is not distinctive of the different senses.
6.2.2 Dictionary clouds
In a few cases we can see clusters characterized by one dominant context word that perfectly match a sense, or at least its clustered tokens. These are normally fixed expressions, at least to a degree: the definition of the sense itself may specify a required expression, such as representatieve staal ‘representative sample.’
An interesting example is shown in Figure 6.2, a model of the noun schaal ‘scale/dish.’ In the plot, the ‘scale’ homonym is represented by circles (‘a range of values, e.g. the scale of Richter, a scale from 1 to 5’), squares (‘magnitude, e.g. on a large scale’) and a few triangles (‘ratio, e.g. a scale of 1:20’), whereas the ‘dish’ homonym is represented by crosses (‘shallow wide dish’) and crossed squares (‘dish of a scale’). Both the ‘range’ and the ‘dish of scale’ senses, exemplified in (11) and (12), have a perfect match (or almost) with an hdbscan cluster, represented by a context word with perfect \(F\)-score. All the schaal tokens co-occurring with Richter are grouped in the red Cumulus cloud, and cover almost the full range of attestations of the ‘range’ sense, and all the tokens co-occurring with gewicht ‘weight’ are grouped in the light blue Cumulus cloud and cover all the attestations of the ‘dish of a scale’ sense. The blue cloud of crosses is also an homogeneous Cumulus dedicated to the ‘shallow wide dish’ sense, but not dominated by a collocate, and the rest are variably homogeneous Stratocumulus clouds representing parts of the ‘magnitude’ sense.
-
Wenen, Beneden-Oostenrijk en Burgenland zijn dinsdagochtend opgeschrikt door een aardschok van 4,8 op de schaal van Richter. (Het Nieuwsblad, 2000-07-12, Art. 4)
‘Vienna, Lower Austria and Burgenland have been scared up on Tuesday morning by an earthquake of 4.8 on the Richter scale.’
-
Daarom is het van belang dat Nederland zich deze week achter de VS heeft geschaard, ook al legt ons land natuurlijk minder gewicht in de schaal dan Duitsland in het Europese debat over de al dan niet noodzakelijke toestemming van de Veiligheidsraad voor militaire actie tegen Irak. (NRC Handelsblad, 2002-09-07, Art. 160)
‘Therefore it is important that the Netherlands has united behind the US this week, even though our country has of course less influence (lit. `places less weight on the dish of the scale’) than Germany in the European debate on the potentially necessary permission of the Security Council for military action against Iraq.’
In a way, the phenomenon indicates a fixed, idiomatic expression: a combination of two or more words that fully represents a sense. However, the picture is more nuanced. First, technically, the ‘range’ sense can potentially occur with more context words than Richter. In fact, one of the examples given to the annotators is schaal van Celsius ‘Celsius scale,’ as well a pattern like the one found in (13), one of the orange circles at the top of Figure 6.2. However, in the corpus used for these studies, Celsius does not co-occur with schaal in a symmetric window of 4; moreover, of the 32 tokens of this sense attested in this model, 22 co-occur with Richter, 3 follow the pattern from (13), and the rest exhibit less fixed patterns or the infrequent glijdende schaal ‘slippery slope’ construction. The few matching (13) are more readily clustered with other tokens co-occurring with the preposition op ‘on,’ such as (14). In other words, in the register of newspapers, the ‘range’ sense of schaal is almost completely exhausted in the schaal van Richter ‘Richter scale’ expression.
-
"Misschien deelt de computer mij op grond van statistische analyses op een schaal van 1 tot 12 in categorie 3", zegt woordvoerder B. Crouwers van de registratiekamer. (NRC Handelsblad, 1999-01-09, Art. 10)
‘"Maybe the computer on the basis of statistical analyses on a scale of 1 to 12 puts me in category 3", says spokesperson B. Crouwers of the registration chamber.’
-
Die stad vormde de opmaat tot de latere collectieve regelingen op nationale schaal, stellen de auteurs, in navolging van socioloog prof. dr. Abram de Swaan. (De Volkskrant, 2003-05-03, Art. 253)
‘That city was the prelude to the later collective arrangements at national level (lit. `on a national scale’), state the authors, in accordance with sociologist Prof. Dr. Abram de Swaan.’
Second, the ‘dish of a scale’ sense need not be used in the metaphorical expression illustrated in (12), but that is indeed the case in our data. Next to gewicht ‘weight,’ these tokens also mostly co-occur with leg ‘to lie, to place’ or, in lesser degree, with werp ‘to throw.’ Even in other models, this cluster tends to be built around the co-occurrence with gewicht ‘weight,’ normally excluding tokens that only co-occur with leg ‘to lie, to place,’ which do not belong to the same sense any more.
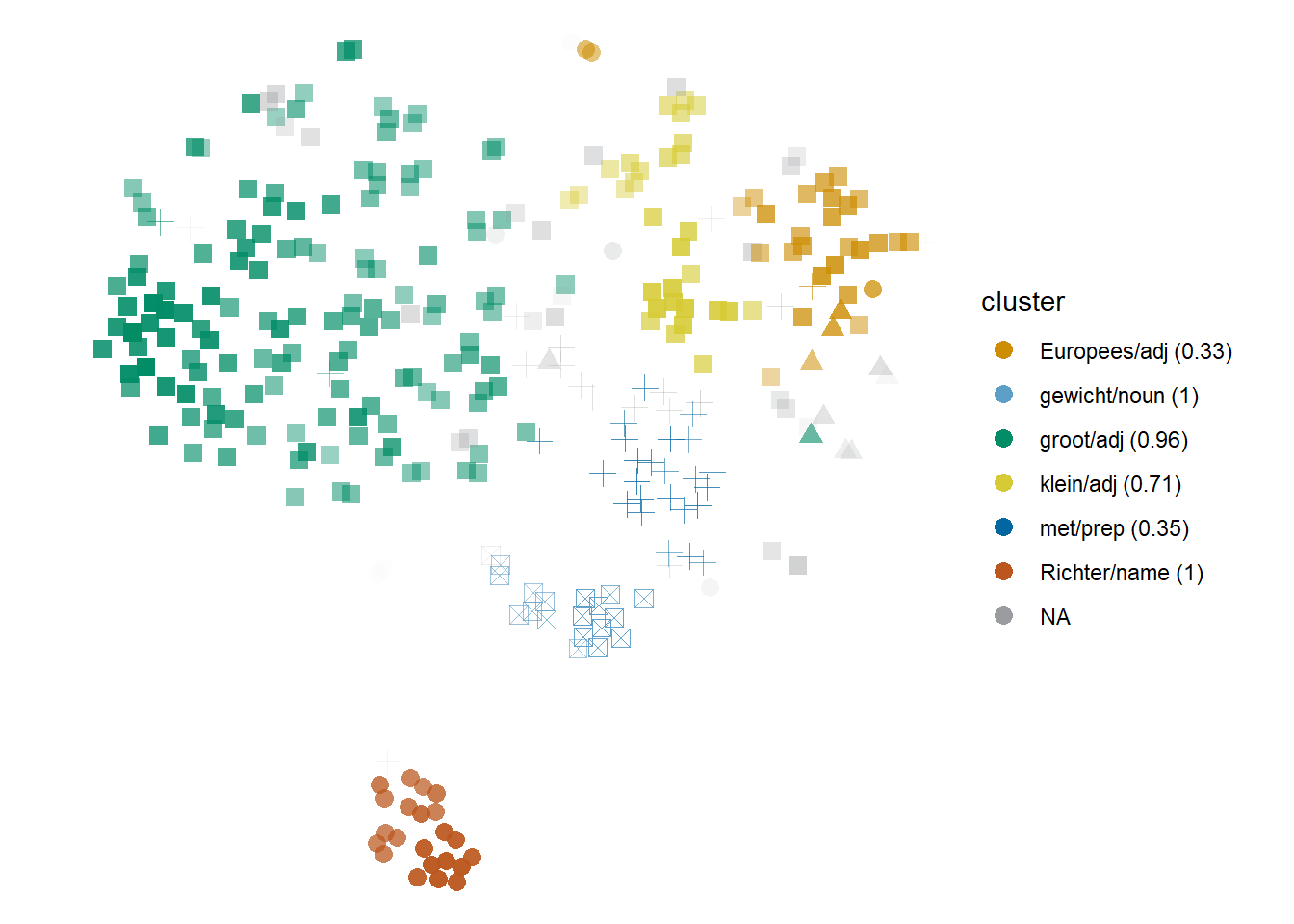
Figure 6.2: Cloud of schaal: nobound5all-ppmiweight-focall. Within the ‘scale’ homonym, circles are ‘range’; triangles, ‘ratio,’ and squares, ‘magnitude’; for the ‘dish’ homonym, crosses represent ‘dish’ and crossed squares, ‘dish of a scale.’
These examples don’t disprove the possibility of clouds dominated by a collocate perfectly covering a sense, as long as we keep in mind the characteristics and limitations of the corpus we are studying and the difference between describing “how a sense is used” and “how a sense is used in this particular corpus.”
6.2.3 (Proto)typical contexts
The most frequent phenomenon among Cumulus and Stratocumulus clouds is a cluster dominated by one context word or group of co-occurring context words that represents a (proto)typical context of a sense. It may be the prototypical context, if the rest of the sense is discarded as noise or spread around less clear clusters, but we might also find multiple clusters representing different typical contexts of the same sense. Neither t-sne nor hdbscan can tell whether one of these contexts is more central than the other, at least not in the same sense we would expect from prototype theory. Denser areas of tokens, as perceived by hdbscan, are those where many tokens are very similar to each other. The more tokens are similar, and the more similar they are, the denser the area. As we will see in this example, this is not a good proxy for prototypicality.
One of the most clear examples of this phenomenon is found in heffen ‘to levy/to lift,’ whose typical objects are also characteristic of its two main senses (see Figure 6.3). On the one hand, the ‘to levy’ sense occurs mostly with belasting ‘tax,’ tol ‘toll’44, and accijns ‘excise,’ as shown in (15) through (17). Their frequencies are large enough to form three distinct clusters, which tend to merge in the following levels of the hdbscan hierarchy, that is, they are closer to each other than to the clusters of the other sense. On the other hand, the ‘to lift’ sense occurs with glas ‘glass,’ where the final expression een glas(je) heffen op takes the metonymical meaning ‘to give a toast to’ (see (18)), and with the body-parts hand, arm and vinger ‘finger,’ in which they might take other metonymical meanings. The latter group does not really belong to this “collocation” category but to “semantic preference” (see Section 6.4).
-
Op het inkomen boven die drie miljoen gulden wil De Waal honderd procent belasting heffen. (Het Parool, 2001-05-02, Art. 99)
‘De Waal wants to levy a one hundred percent tax on all incomes above that three million guilders.’
-
Mobiliteitsproblemen, rekeningrijden, op een andere manier het gebruik van de weg belasten, kilometers tellen, tol heffen — de mogelijkheden om de ingebouwde chip te benutten zijn vrijwel onbeperkt. (NRC Handelsblad, 1999-10-02, Art. 31)
‘Mobility problems, road pricing, taxing the use of roads in a different way, counting kilometres, levying taxes — the possibilities to utilize the built-in chip are almost unlimited.’
-
…in landen als Groot-Brittannië (waar de accijnzen op 742 euro per 1.000 liter liggen), Italië en Duitsland (die beide accijnzen boven de 400 euro heffen) komt de harmonisering ten goede van de transportsector. (De Morgen, 2002-07-25, Art. 104)
‘…in countries like Great Britain (where excise duties are at 742 euros per 1,000 liters), Italy and Germany (both of which levy excise duties above 400 euros) the transport sector benefits from the harmonization.’
-
Nog twaalf andere deelnemers konden maandagavond het glas heffen op de hoogste winst. (De Standaard, 2004-10-20, Art. 150)
‘On Monday night another twelve participants could raise their glasses to the highest profit.’
As we can see in Figure 6.3, the model is very successful at separating the two senses and the clusters are semantically homogeneous: the most relevant collocates of heffen ‘to levy/to lift’ are distinctive of one or the other of its senses. Crucially, no single cluster is even close to covering a full sense; instead, each of them represents a prototypical pattern that stands out due to its frequency, internal coherence and distinctiveness. It seems reasonable to map the clusters to prototypical patterns because of their frequency and distinctiveness, but we should be careful about how we apply the results of the modelling to this kind of semantic analysis. From the perspective of prototype theory, a feature of a category is more central if it is more frequent, i.e. it is shared by more members, while a member is more central if it exhibits more of the defining features of the categories. As such, within the ‘to levy’ sense, the belasting heffen ‘to levy taxes’ pattern is the most central, and tokens instantiating such a pattern will be more central. In contrast, hdbscan prioritizes dense areas, that is, groups of tokens that are very similar to each other. Thus, membership probabilities, which we might be tempted to use as proxy for centrality, indicate internal consistency, lack of variation. From such a perspective, given that belasting heffen ‘to levy taxes’ is more frequent and applies to a wider variety of contexts than the other two patterns of ‘to levy,’ its area is less dense, and its tokens have lower membership probabilities within a compound of ‘to levy’ clusters. In other words, the models can offer us typical patterns of a lemma and of its senses and tell us how distinctive they are from each other and how much internal variation they present. Beyond this information, they don’t map in a straightforward manner to our understanding of prototypicality.

Figure 6.3: Cloud of heffen: bound10all-ppmiweight-focnav. Circles are ‘to lift,’ triangles are ‘to levy.’
It must be noted that clusters defined by collocations may not be just characterized by one single context word, but by multiple partially co-occurring context words. A clear example is hachelijk ‘dangerous/critical,’ where both senses are characterized by prototypical contexts, exemplified in (19) through (24): onderneming ‘undertaking,’ zaak ‘business’ and avontuur ‘adventure’ for the ‘dangerous, risky’ sense, moment, situatie ‘situation,’ and positie ‘position’ for the ‘critical, hazardous’ sense. A model is shown in Figure 6.4, where only the yellow, orange and green clusters are Cumulus clouds, and the rest, Stratocumulus. These six frequent context words are paradigmatic alternatives of each other, all taking the slot of the modified noun, i.e. the entity characterized as dangerous or critical. However, unlike its very near type-level neighbour situatie ‘situation,’ positie ‘position’ may also co-occur with bevrijd ‘to free’ (and uit ‘from’) and, additionally, with brandweer ‘firefighter,’ typically in Belgian contexts. The frequency of these co-occurrences in the sample, next to the type-level dissimilarity between these three lexical items, splits the co-occurrences with positie ‘position’ in three clusters (in light blue, green and red in Figure 6.4), based on these combinations.
-
Het is geen gewaagde stelling dat de deelname van de LPF aan de regering een hachelijke onderneming blijft. (De Volkskrant, 2002-08-05, Art. 46)
‘It is not a bold statement that the participation of the LPF in the government remains a risky undertaking.’
-
Daar baseerden de media zich op slechts één bron, en elke journalist weet dat dat een hachelijke zaak is. (De Volkskrant, 2004-05-05, Art. 42)
‘The media relied on only one source, and every journalist knows that that is a dangerous thing to do.’
-
…met storm opzij is het inhalen van een vrachtwagen een hachelijk avontuur… (Het Parool, 2000-03-17, Art. 34)
‘…under sidewind conditions overtaking a truck is a risky adventure…’
-
Kortrijk beleefde enkele hachelijke momenten tegen Brussels, dat in zijn ondiep bad bewees zijn vierde plaats in de play-offs waard te zijn. (Het Laatste Nieuws, 2001-05-14, Art. 375)
‘Kortrijk experienced some critical moments against Brussels, who in their shallow pool proved to be worthy of their fourth place in the play-offs.’
-
Kort maar krachtig staat er: ``De hachelijke situatie van Palestina is vooral een interne aangelegenheid, hoewel de bezetting en de confrontatie met Israël er de context voor schept." (De Standaard, 2004-10-02, Art. 162)
‘Short but powerful, it reads: ``The critical situation in Palestine is mostly an internal matter, even though the occupation and the confrontation with Israel create the context for it."’
-
Zij toont knappe filmpjes, opgenomen vanuit de hachelijke positie van een deltavlieger… (De Morgen, 1999-06-07, Art. 126)
‘She shows outstanding videos, taken from the hazardous position of a hang glider…’
The model does not give us information about the relative centrality of the three positie clusters. They result from the combination of three features, and each cluster exhibits a different degree of membership based on how many of these overlapping features it co-occurs with. At the same time, they have a distinctive regional distribution. Based on this data, we might said that a prototypical context of hachelijke posities ‘dangerous/critical positions’ in Flanders is a situation in which firefighters free someone/something from them, while this core is not present, or at least not nearly as relevant, in the Netherlandic data. We might also say that the same situation is not typical of hachelijke situaties ‘dangerous/critical situations,’ and this therefore presents a (local) distributional difference between two types that otherwise, at corpus level, are near neighbours.
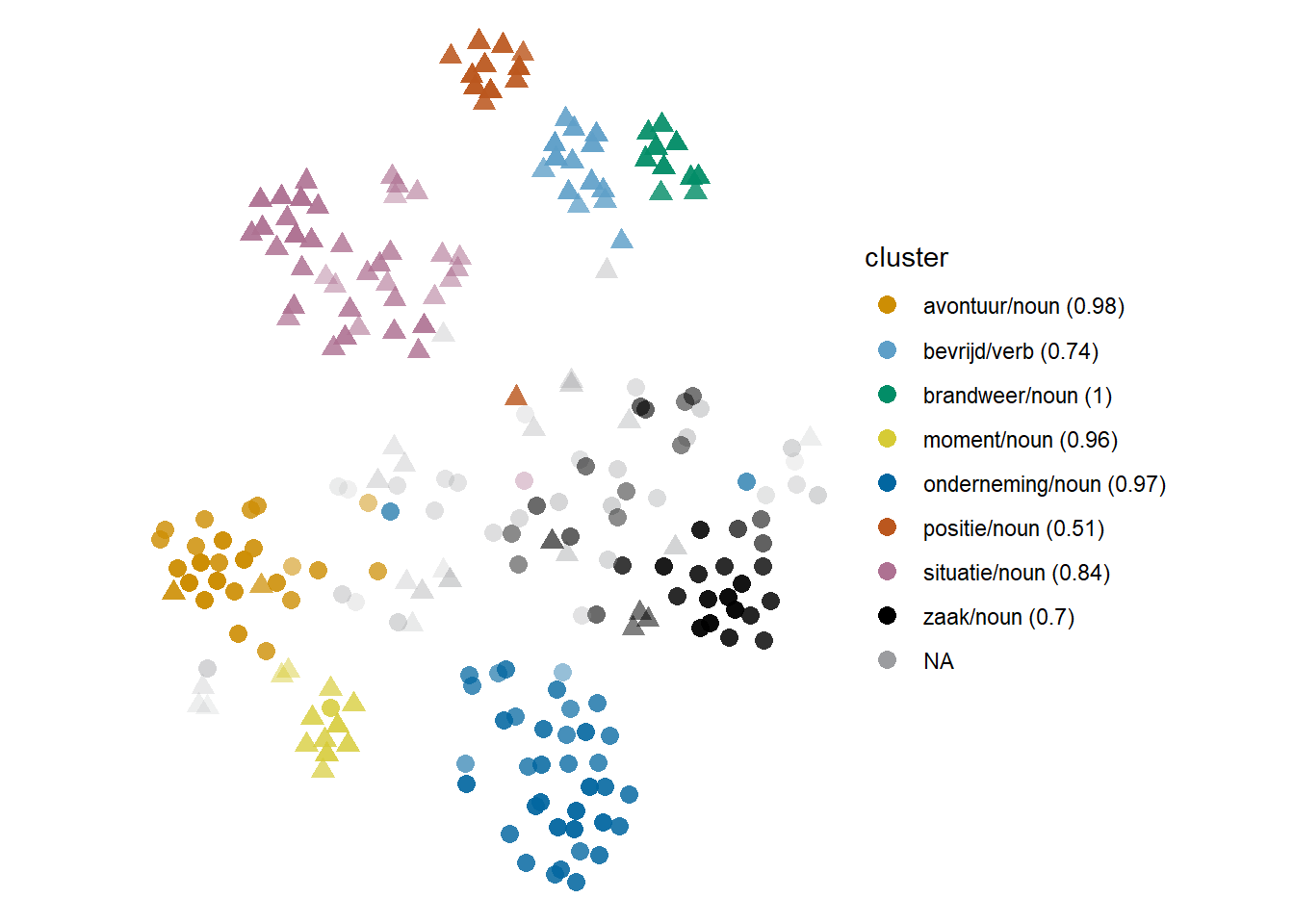
Figure 6.4: Cloud of hachelijk: bound5all-ppmiweight-focall. Circles are ‘dangerous, risky’; triangles are ‘critical, hazardous.’
6.2.4 Profiling
Clusters dominated by a context word may not only represent a typical context within a sense, but also one that highlights a different dimension of such sense than other clusters. This is not extremely frequent and requires an extra layer of interpretation, but it is an additional explanation to some of the clustering solutions.
One example is given by the ‘substance’ meaning of stof, represented as circles in Figure 6.5. Within this sense, we tend to find clusters dominated by gevaarlijk ‘dangerous,’ schadelijk ‘harmful’ (which also attracts kankerwekkend ‘carcinogenic’) and giftig ‘poisonous’ (which often attracts chemisch ‘chemical’). These dominant context words are nearest neighbours at type-level, and the clusters they govern belong to the same branch in the hdbscan hierarchy.
However, we can find additional information, among the context words that co-occur with them, which suggests that frequency is not the only responsible for their separated clusters. Concretely, the tokens in the cluster dominated by schadelijk ‘harmful’ tend to focus on the environment and composition of substances, as indicated by the co-occurrence with uitstoot ‘emissions,’ lucht ‘air,’ stank ‘stench’ and bevat ‘to contain’; meanwhile, those in the cluster dominated by giftig ‘poisonous’ focus on the context of drugs or profile the liberation of substances, with context words such as vorm ‘to form,’ kom_vrij ‘to be released’ and drugs_gebruik ‘drug use.’ The clusters are not distinguished by their meaning as it would be coded in a dictionary entry, but by semantic dimensions that are highlighted in some contexts and hidden in others, but always latent. This effect of the less frequent context words is one of the consequences of less restrictive models: at some levels of analysis, one word (gevaarlijk ‘dangerous,’ schadelijk ‘harmful’…) might be enough to disambiguate the target, but this extra information enriches our understanding of how the words are actually used. It is also contextualized information: not just about how stof ‘substance’ is used, but how it is used when in combination with certain frequent collocates.
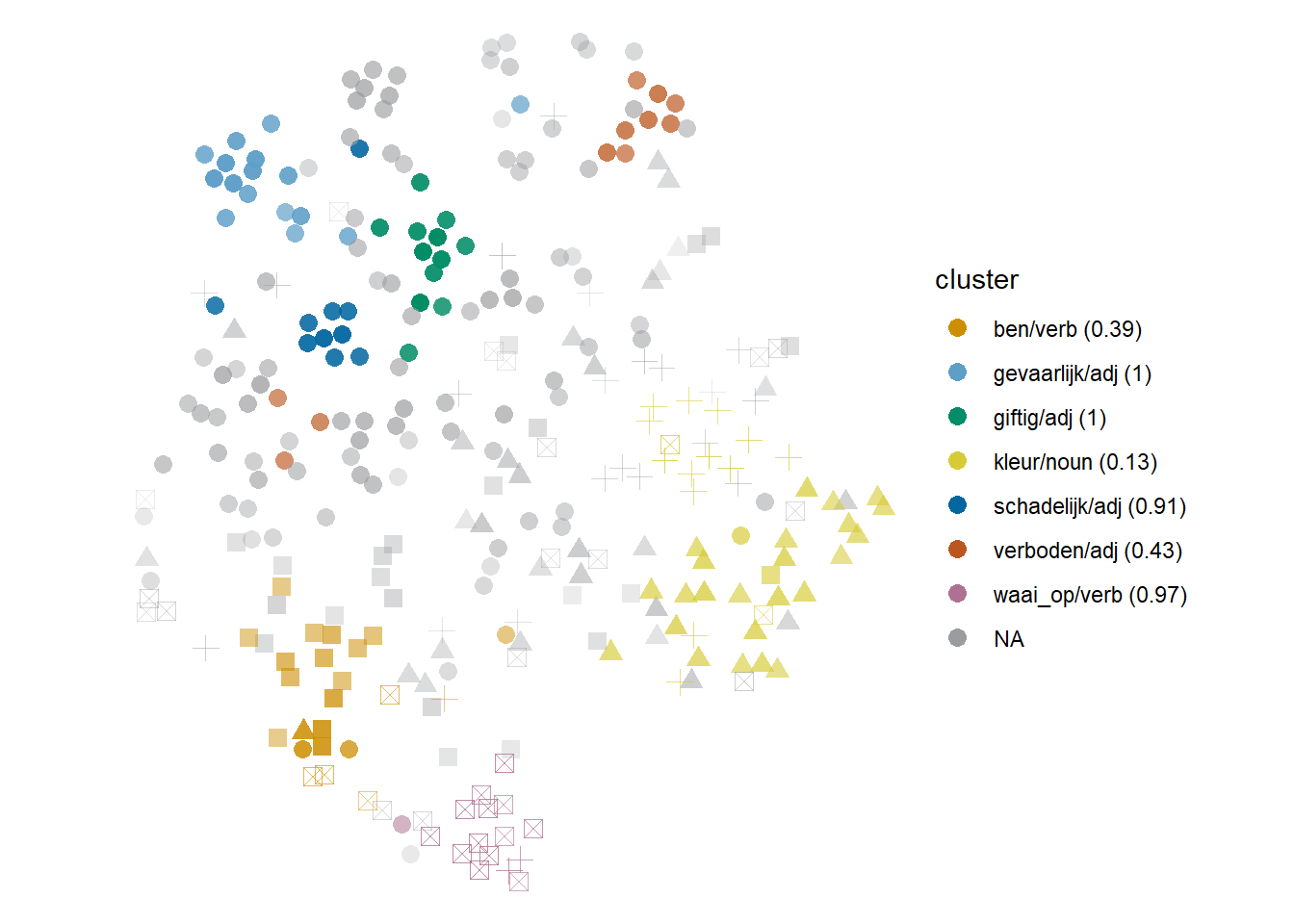
Figure 6.5: Cloud of stof: bound5lex-ppmiselection-focall. Within the first homonym, circles are ‘substance’; triangles, ‘fabric’; filled squares, ‘topic, material.’ For the second, crosses are literal ‘dust’ and crossed square, idiomatic expressions.
6.3 Lexically instantiated colligation
Even without relying on part-of-speech tags or dependency relationships as features for our models, we can obtain grammatical information from lexical collocates. For example, the passive auxiliary word indicates passive constructions, as well as the somewhat less frequent preposition door, which indicates an explicit agent, much like by in English. Other constructions might also be indicated by key function words, such as om te ‘in order to,’ dat ‘that’ for relative clauses, dan ‘than’ for comparatives, and prepositions. The patterns that emerge from clusters with lexically instantiated colligation may cross the boundaries of dictionary senses — resulting in heterogeneous clusters — match senses, or indicate a prototypical configuration within a sense. The following subsections explore examples of these different phenomena.
6.3.1 Heterogeneous clusters
The verb herstructureren ‘to restructure’ was annotated with three sense tags emerging from a combination of specialization, i.e. whether it’s specifically applied to companies, and argument structure, distinguishing between transitive and intransitive herstructureren. The intransitive sense is always specific — companies restructure, undergo a process of restructure.
Models are typically not very successful at disentangling these three senses, or any one of them, for that matter. Instead, the clusters that emerge tend to highlight either the semantic or the syntactic dimension, disregarding the other one. The lexical items that most frequently dominate clusters of herstructureren ‘to restructure’ are the passive auxiliary word, bedrijf ‘company,’ grondig ‘thorough(ly),’ and the pair of prepositions om te ‘in order to,’ as illustrated in (25) through (27).
-
OK-score deelt bedrijven op in tien klassen; klasse 1 blaakt van gezondheid, klasse 10 is op sterven na dood, ofwel, staat op de rand van faillissement en moet grondig worden geherstructureerd. (Het Parool, 2003-04-16, Art. 69)
‘The OK-score divides companies into ten classes: class 1 is brimming with health, class 10 is as good as dead, or rather, stands on the edge of bankruptcy and must be thoroughly restructured.’
-
Ze herstructureerden het bedrijf en loodsten het de internationale groep Taylor Nelson Sofres (TNS) binnen. (De Standaard, 2004-01-06, Art. 59)
‘They restructured the company and steered it towards the Taylor Nelson Sofres (TNS) international group.’
-
Uiteindelijk is dat de regering, want toen de crisis uitbrak nam de overheid een belang in de banken om ze te herstructureren en uiteindelijk weer te verkopen. (NRC Handelsblad, 2000-11-07, Art. 11)
‘In the end that is the government, because when the crisis hit the authorities took an interest in the banks in order to restructure them and eventually sell them again.’
The two nouns never co-occur, and only occasionally co-occur with word or om te, which themselves co-occur a few times. Both grondig ‘thorough(ly)’ and bedrijf ‘company’ are good cues for the company-specific senses, but may occur with either transitive or intransitive constructions. In contrast, word is a good cue for transitive (specifically, passive) constructions, but may occur with either the company-specific or the general sense. Finally, om te may be attested in either of the three senses. The stark separation of the clusters in Figure 6.6 would seem to suggest opposite poles, but that is not the case at the semantic level. In fact, unlike Figures 6.3 or 6.4, dominated by Cumulus and Stratocumulus clouds, the clusters are merely slightly denser areas in a rather uniform, noisy mass of tokens — the green cloud is a Stratocumulus and the other two are Cirrus clouds — and would be much harder for the naked human eye to capture without hdbscan input. Instead, each cluster indicates a pole of contextual behaviour which itself may code a semantic dimension, in the case of the bedrijf ‘company’ cluster, or a syntactic one, as in the lexically instantiated colligation clusters.
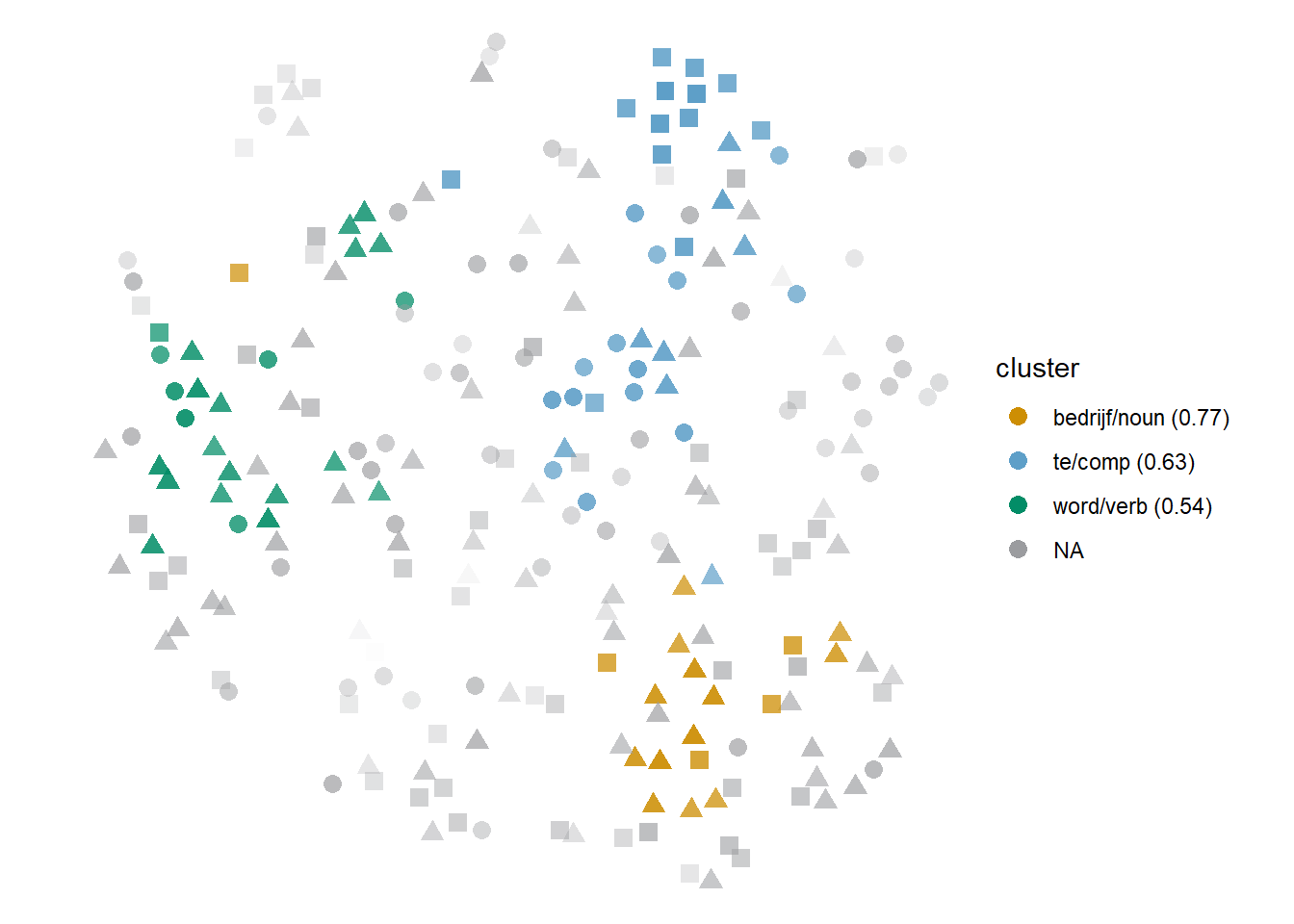
Figure 6.6: Cloud of herstructureren: bound3all-ppmiselection-focall. Circles indicate the transitive, general sense; triangles, the transitive companies-specific sense, and squares, the intransitive (companies-specific) sense.
6.3.2 Dictionary clouds
While a rare thing, we might be able to find a cluster dominated by a grammatical pattern that matches a dictionary sense. One clear case is the reflexive sense of herhalen ‘to repeat,’ characterized by its co-occurrence with zich ‘itself’ in BOW models without part-of-speech filters (all) and in REL models, especially if PPMIweight is applied too.45
In the model shown in Figure 6.7, it is the clearest cluster, the red Stratocumulus of squares at the bottom. Looking closely, we can see that it is made of two halves: a small one on the left, in which the tokens also co-occur with geschiedenis ‘history,’ and a bigger one on the right, where they do not. This particular model is very restrictive: it normally captures only one or two context words per token, which is all that we need to capture this particular sense.
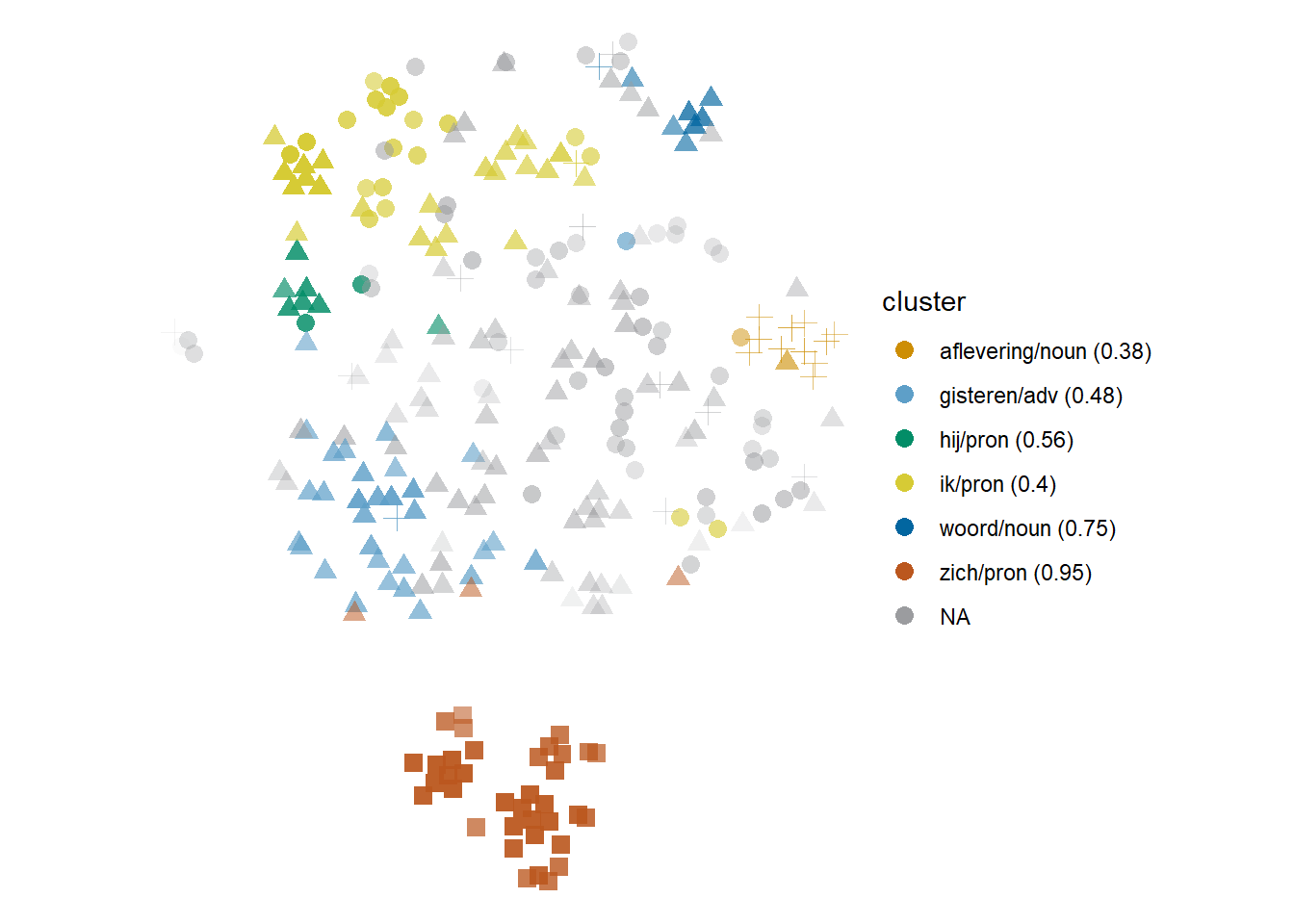
Figure 6.7: Cloud of herhalen: rel1-ppmiselection-focall. Circles are ‘to do again’; triangles, ‘to say again’; squares, ‘(reflexive) to happen again,’ and crosses, ‘to broadcast again.’
We expected this kind of output in other lemmas with purely reflexive senses as well, but it is not easy to achieve. In the case of diskwalificeren ‘to disqualify,’ the very infrequent reflexive sense is typically (but not always) absorbed within the transitive sense that matches it semantically, i.e. the non sports-related sense. Alternatively, a lexically instantiated colligation may prefer a certain sense without exhausting its attestations: in that case, it represents a prototypical context, as shown in the following section.
6.3.3 (Proto)typical contexts
The verb herinneren has two main senses defined by well defined constructions: either an intransitive construction co-occurring with the preposition aan, meaning ‘to remind,’ or a reflexive construction meaning ‘to remember’; a third, transitive sense is also attested but very infrequently. This lemma is sometimes rendered as three equally sized Stratocumulus clouds, as shown in Figure 6.8: the orange cluster is characterized by the preposition aan (see (28)), the green one by the subject and reflexive first person pronouns ik and me (see (29)), and the yellow one by the third person reflexive pronoun zich (see (30)). A smaller group of tokens co-occurring with eraan, a compound of the particle er and aan (see example (31), where it works as a placeholder to connects the preposition to a subordinate clause), may form its own Cumulus cloud, like the light blue one in Figure 6.8, or be absorbed by one of the larger ones.
-
Vinocur herinnert aan een tekening van Plantu in L’Express. (Het Parool, 2002-05-18, Art. 101)
‘Vinocur reminds [the spectator] of a drawing by Plantu in L’Express.’
-
Ik herinner me een concert waarop hij hevig gesticulerend applaus in ontvangst kwam nemen. (Het Parool, 2003-11-14, Art. 79)
‘I remember a concert in which he received a round of overwhelming applause.’
-
"Het was die dag bloedheet", herinnert de atlete uit Sint-Andries zich nog levendig. (Het Nieuwsblad, 2001-08-08, Art. 192)
‘"It was scorching hot that day", remembers the athlete from Sint-Andries vividly.’
-
In zijn voorwoord herinnert Manara eraan dat deze meisjes in hun tijd vaak met toegeknepen oogjes werden aanschouwd. (De Morgen, 2001-11-10, Art. 40)
‘In his preface Manara reminds [the reader] that back in their time these girls were often looked at with squinted eyes.’
As the shape coding in the plot indicates, the clusters are semantically homogeneous46, because these function words are perfect cues for the senses. The rest of the co-occurring context words do not make a difference: they are not strong enough, in the face of these pronouns and prepositions, to originate further salient structure. Nonetheless, both the aan and eraan clusters on one side, and the pronoun-based clusters on the other, belong to the same sense. Thus, what these lexically instantiated colligation clusters represent is a typical or salient pattern within each sense.

Figure 6.8: Cloud of herinneren: bound10all-ppmiweight-5000nav. Circles indicate ‘to remind’ (with aan); triangles, ‘(reflexive) to remember,’ and (the very few) squares, ‘(trans.) to remember.’
6.3.4 Profiling
Like clusters defined by collocations, clusters defined by lexically instantiated colligations can also represent a typical context that highlights a specific dimension of the sense of the target. One such case is found in the ‘horde’ sense of horde, whose most salient collocates in this corpus are toerist ‘tourist’ and journalist. The two collocates are quite similar to each other at type-level, but the rest of the context words in their clusters point towards a different dimension of the ‘horde’ sense: hordes of journalists, photographers and fans (other nouns present in the same cluster) will surround and follow celebrities, as suggested by the co-occurrence of omring ‘to surround,’ wacht_op ‘to wait’ and achtervolg ‘to chase,’ among others. In contrast, hordes of tourists will instead flood and move around in the city, with words such as stroom_toe ‘to flood’ and stad ‘city.’ As it stands, the situation is equivalent to the case of stof ‘substance’ described above. However, in the models that capture function words like the one shown in Figure 6.9, the profiling in these clusters is strengthened by lexically instantiated colligations. The journalist cluster is dominated by the preposition door, which signals explicit agents in passive constructions; the passive auxiliary word also occurs, albeit less frequently. Meanwhile, the toerist ‘tourist’ cluster includes tokens co-occurring with naar ‘towards.’ The prepositions are coherent with the dimensions of ‘horde’ highlighted by each of the clusters, i.e. aggressivity and flow respectively. Interestingly, they don’t co-occur with all the tokens that also co-occur with journalist and toerist ‘tourist’ respectively, but the nouns and prepositions complement each other instead.
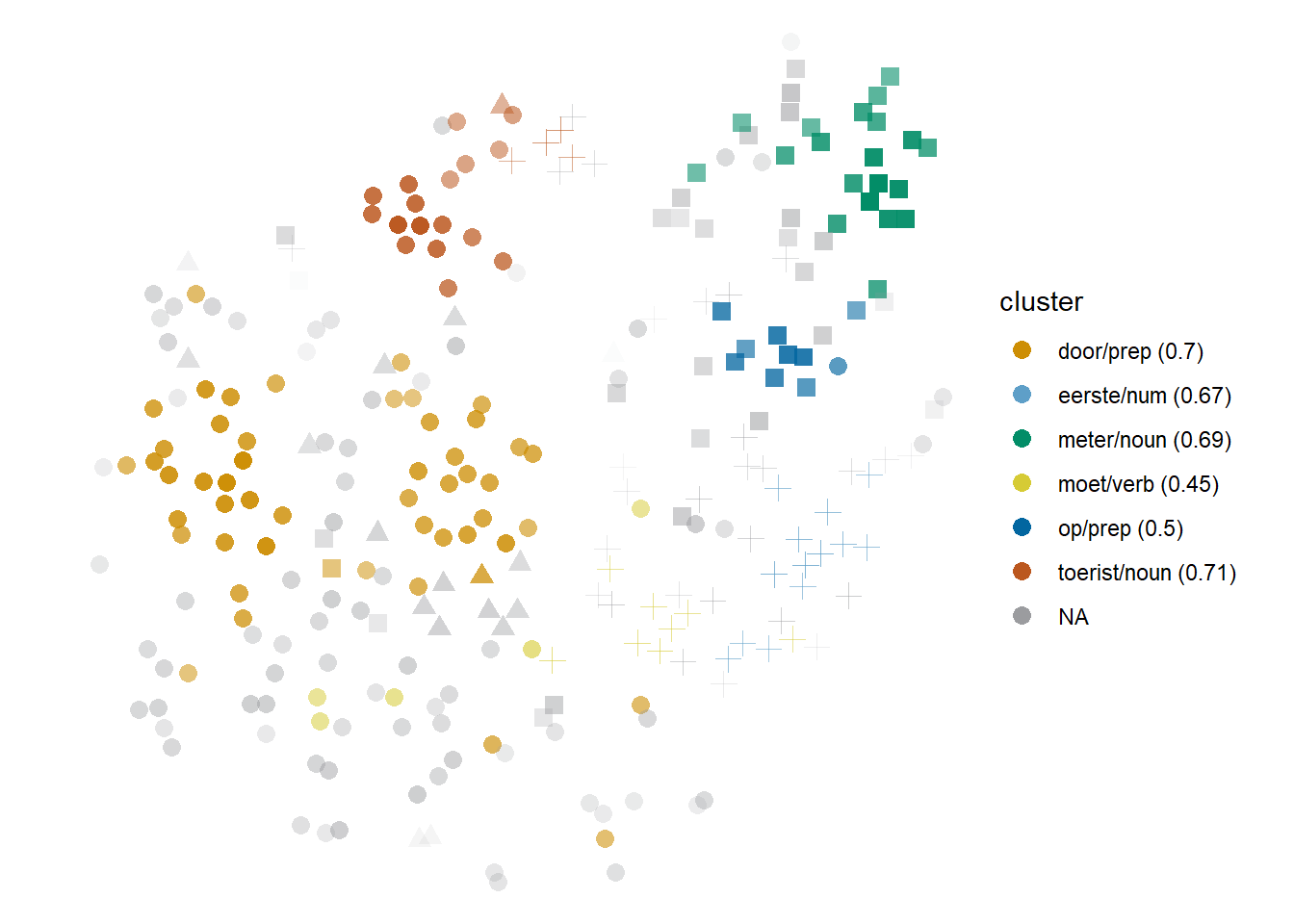
Figure 6.9: Cloud of horde: bound5all-ppmiselection-focall. Within the ‘horde’ homonym, circles indicate human members and triangles, nonhuman members; within the ‘hurdle’ homonym, squares show the literal sense and crosses, the metaphorical one.
6.4 Semantic preference
Clusters that are not clearly dominated by one context word or group of co-occurring context words, be they lexical collocations or lexically instantiated colligations, may still be the result of coherent distributional and semantic patterns. Representing first-order context words with their type-level vectors allows infrequent near neighbours to join forces and approximate the effect of one context word with their cumulative frequency. These context words may occur one to four times in the sample, that is, in about one every hundred occurrences of the target, but together with other similar context words, they form a visible pattern.
6.4.1 Heterogeneous clusters
Just like we can have clusters dominated by one context word that is not characteristic of one sense, we can have clusters dominated by multiple similar context words that are not characteristic of any sense. This is the case of names of colours and clothing terms47 co-occurring with grijs ‘gray,’ which in a model like the one shown in Figure 6.10 also includes haar ‘hair.’ As a result, grijs ‘gray’ tokens referring to concrete grey objects in general and, specifically, to grey/white hair, form the light blue Stratocumulus cloud on the top right of the figure. Note that, visually, the two senses occupy opposite halves of this cluster: the haar ‘hair’ tokens (squares) occupy their own space, but the type-level similarity of the context word to the names of colours and clothing terms makes them indistinguishable to hdbscan.
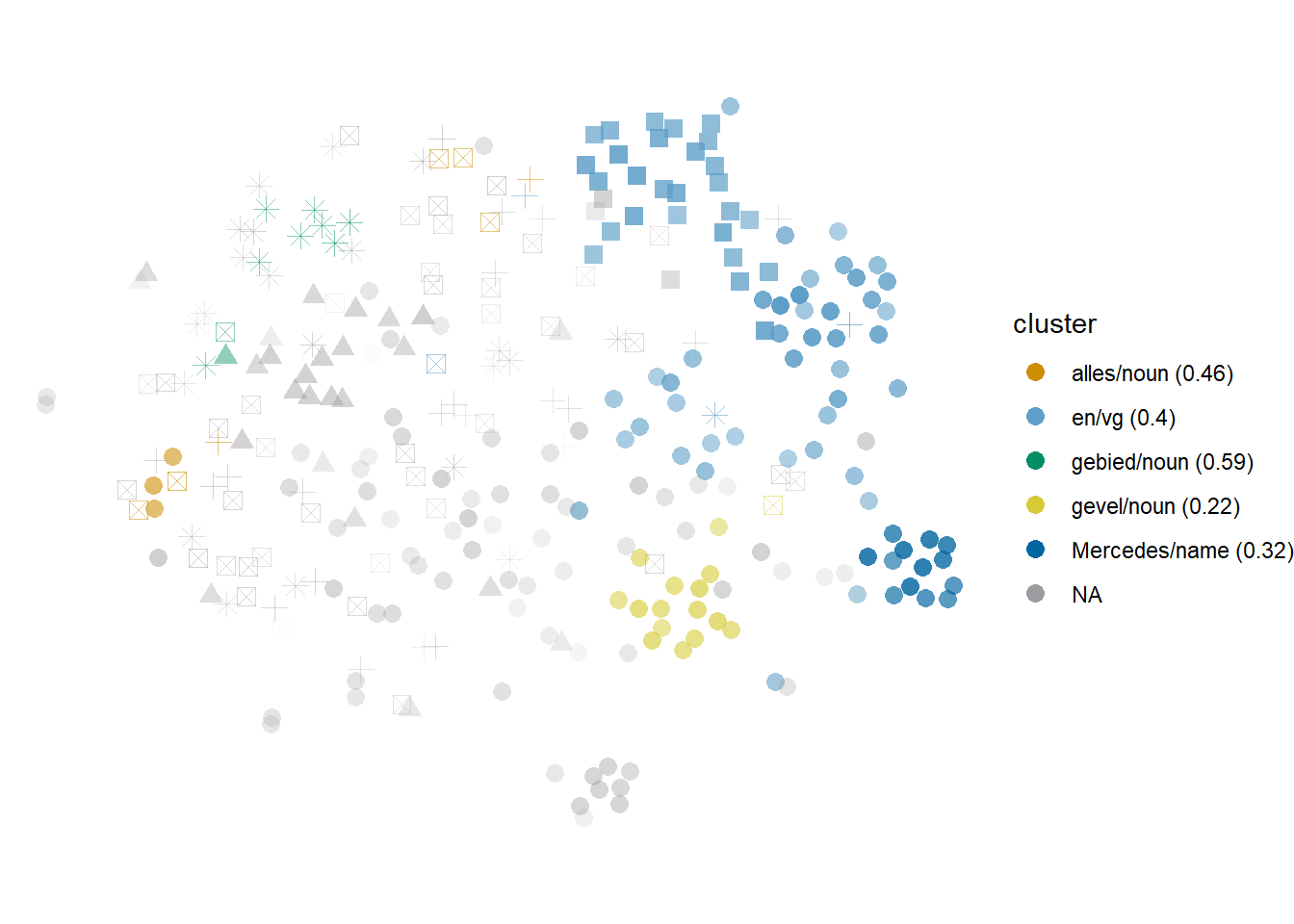
Figure 6.10: Cloud of grijs: bound5all-ppmino-focall. Circles represent the literal sense; triangles, ‘overcast’; squares and crosses, to applications to hair and white-haired people respectively; crossed squares, ‘boring,’ and asterisks, ‘half legal.’
A second example is the set of juridical terms in herroepen, which means ‘to recant’ when the object is a statement or opinion, and ‘to annul, to void’ when it is a law or decision. In the QLVLNewsCorpus, it is often used in a broad legal or juridical context. However, one of the most frequent collocates of herroepen within this field is uitspraak, which can either mean ‘verdict,’ therefore invoking the ‘to void’ sense like in (32), or ‘statement,’ to which ‘to recant’ applies, like in (33). Unfortunately, the broader context is not clear enough for the models to disambiguate the appropriate meaning of uitspraak herroepen in each instance. At the type-level, uitspraak is very close to a number of context words of the juridical field, namely rechtbank ‘court,’ vonnis ‘sentence,’ veroordeling ‘conviction,’ etc. Together, they constitute the semantic preference of the light blue Stratocumulus cloud in Figure 6.11, which, similar to the grijs haar ‘gray/white hair’ situation above, is visually split between the tokens co-occurring with uitspraak and those co-occurring with the rest of the juridical terms.
-
Het beroepscomité herriep gisteren de uitspraak van de licentiecommissie en besliste om KV Mechelen toch zijn licentie te geven. (De Standaard, 2002-05-04, Art. 95)
‘Yesterday the court of appeal voided the verdict from the licencing committee and instead decided to grant KV Mechelen a licence.’
-
Onder druk van Commissievoorzitter Prodi heeft Nielson verklaard dat hij verkeerd is geïnterpreteerd, maar hij heeft zijn uitspraak niet herroepen. (NRC Handelsblad, 2001-10-04, Art. 79)
‘Under pressure from committee chairman Prodi, Nielson declared that he had been misinterpreted, but he did not recant his statement.’
The result is understandable and interpretable: the context words co-occurring with the tokens in the light blue cluster belong to a semantically coherent set and are distributional near neighbours. The problem is that, in the sample, the sense of uitspraak that occurs the most is not the juridical one like in (32) but ‘statement’ like in (33), therefore representing a different sense of herroepen than its juridical siblings. In some models, the two groups are split as different clusters, but in those like the one shown in Figure 6.11, they form a heterogeneous cluster generated by semantic preference.
Interestingly, verklaring ‘statement’ and bekentenis ‘confession’ could be considered part of the same semantic field as well, in broad terms. However, they belong to a different frame within the same field of legal action — a different stage of the process — and, correspondingly, their type-level vectors are different and they tend to represent distinct, homogeneous clusters (the green Cumulus in the figure).
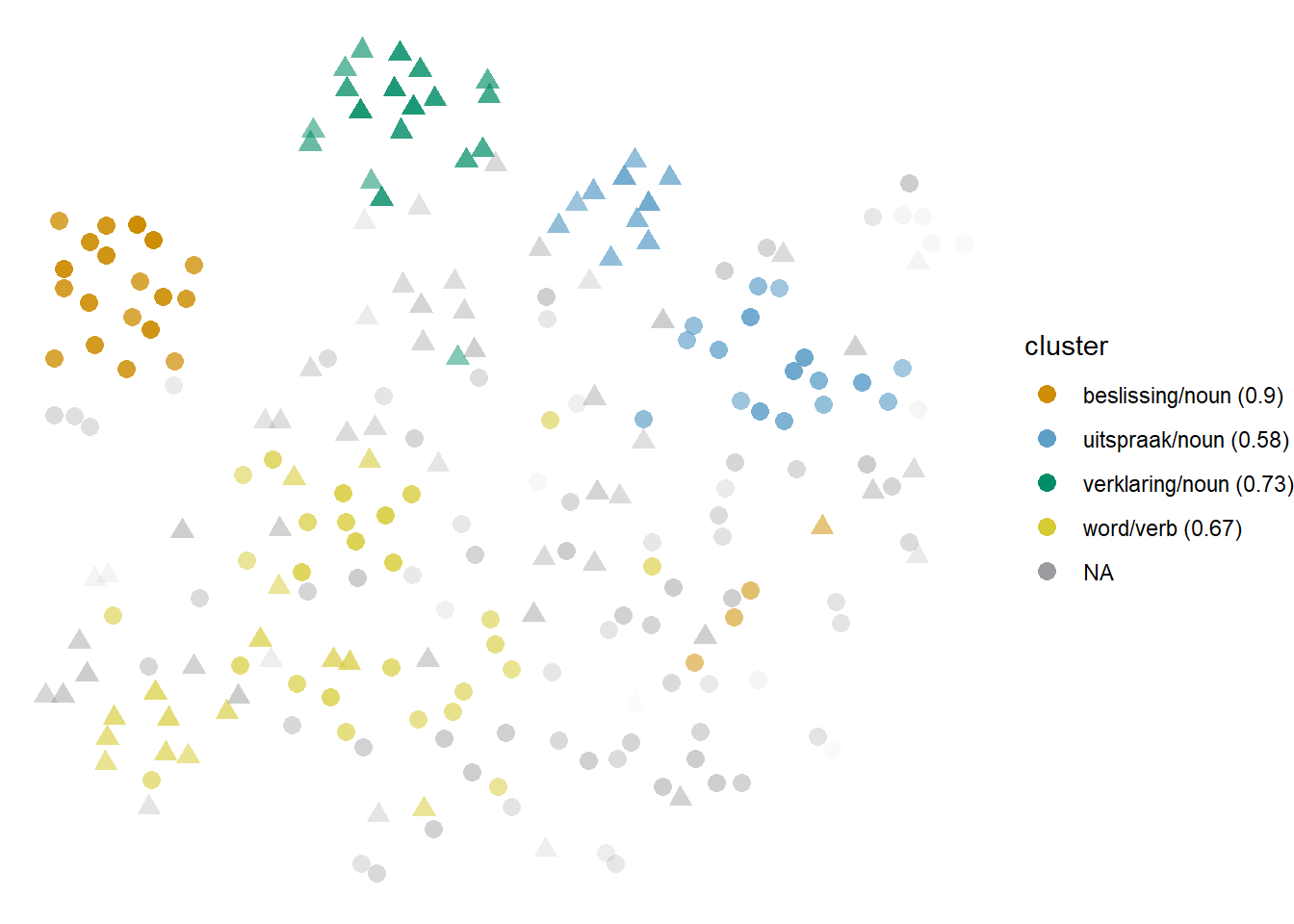
Figure 6.11: Cloud of herroepen: bound3all-ppmiselection-focall. Circles represent ‘to void’; triangles, ‘to recant.’
6.4.2 Dictionary clusters
A few senses can be completely clustered by groups of similar context words. One of these cases was already discussed in the context of schaal ‘scale’ tokens: in models that exclude Richter because of its part-of-speech tag name, the tokens co-occurring with it can alternatively be grouped by kracht ‘power,’ aardbeving ‘earthquake’ and related context words. As in the case of Richter as dominating collocate, the semantic field of earthquakes is not part of the definition of the ‘range’ sense of schaal, but the dominating semantic pattern within the corpus under study.
Another example is found in haken, where the ‘to make someone trip’ sense is characterized by a variety of football-related terms (strafschop ‘penalty kick,’ penalty, scheidsrechter ‘referee,’ etc.), and the very infrequent ‘crochet’ sense, by brei ‘to knit,’ naai ‘to sew,’ hobby and similar words. They are represented as a Stratocumulus of dark blue squares and a Cirrus of light blue crossed squares in Figure 6.12 respectively. As indicated by the name of the dark blue cluster, the passive auxiliary word is also characteristic of the ‘to make someone trip’ cluster and very rarely occurs outside of it: here, lexically instantiated colligation is working together with the clear semantic preference of the cloud.
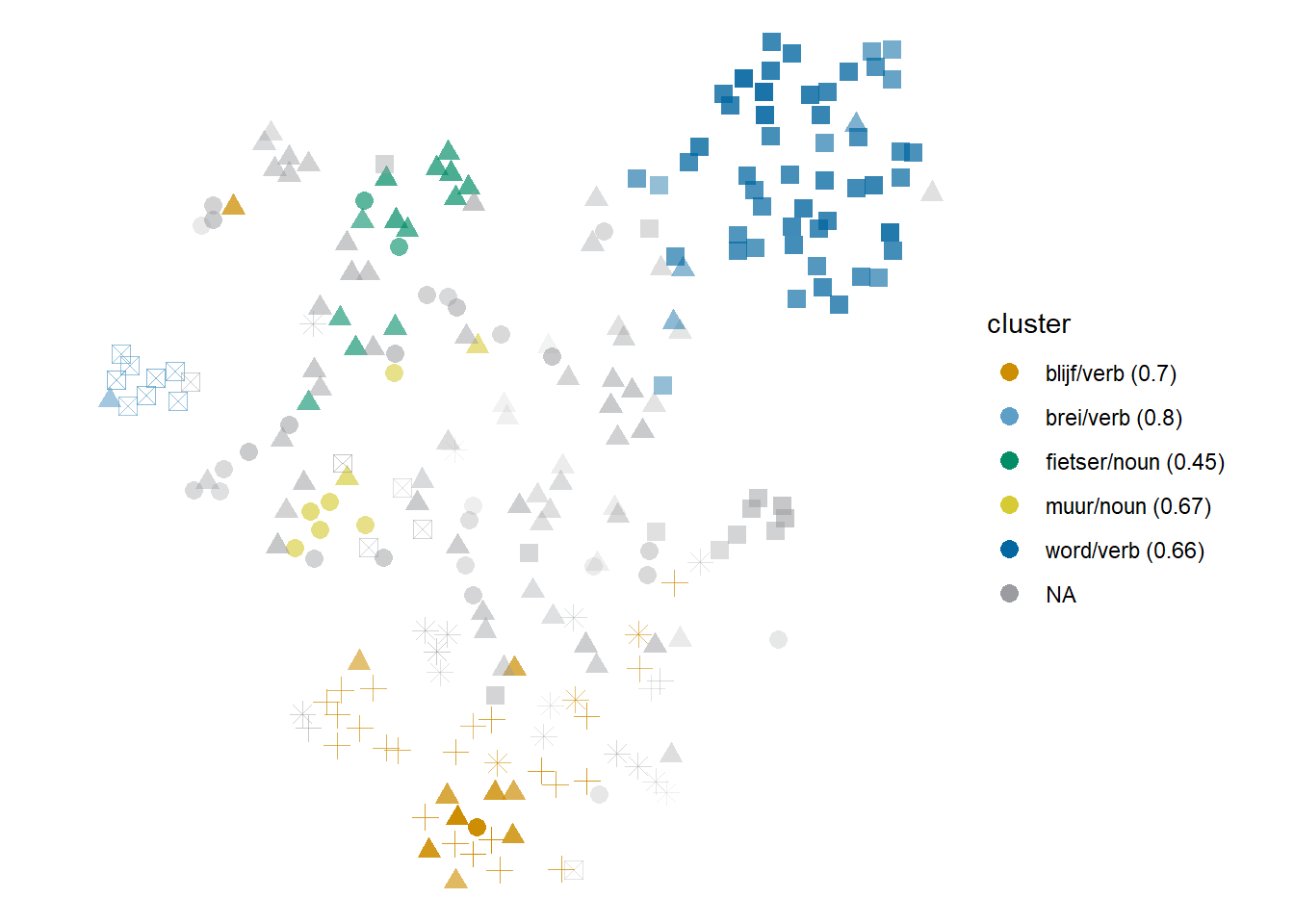
Figure 6.12: Cloud of haken: bound10lex-ppmiselection-focnav. Circles and triangles represent the transitive and intransitive literal ‘to hook’; crosses represent the figurative (intransitive) sense; filled squares represent ‘to make someone trip’; crossed squares, ‘to corchet,’ and asterisks, ‘to strive for’ (with naar).
6.4.3 (Proto)typical contexts
There are several examples of clusters defined by semantically similar infrequent context words representing typical contexts of a sense. In Figure 6.10, for example, the dark blue Stratocumulus is represented by cars, mostly indicated by Mercedes and Opel, next to other brands. In the case of lemmas like dof ‘dull,’ some models might dedicate different clusters to specific collocates, such as klink ‘to sound,’ knal ‘bang,’ klap ‘clap’ and dreun ‘pounding,’ while others group them together in one large cluster defined by a semantic preference indicative of a sense, e.g. sounds.
A typical semantic group attested in different lemmas is culinary: found with schaal ‘dish’ — the blue Cumulus of crosses in Figure 6.10 — and with heet ‘hot,’ the red Stratocumulus of mostly circles in Figure 6.13. In the case of heet ‘hot,’ almost all the tokens co-occurring in this cluster refer to literally hot foods and drinks, although the full expression might be idiomatic, like in (34), and only a few of them belong to the much less frequent sense ‘spicy.’ In other models, the tokens co-occurring with soep ‘soup’ and/or those co-occurring with water tokens might form separate clusters.
-
Hoogstwaarschijnlijk zal Poetin Ruslands afgeknapte westerse partners discreet laten weten dat zodra hij eenmaal in het Kremlin zit, de soep minder heet gegeten zal worden. (De Volkskrant, 1999-12-21, Art. 22)
‘Most probably Putin will discretely let Russia’s former western allies know that as soon as he is in the Kremlin, things will look up (lit. `the soep will be eaten less hot’).’
In addition, aardappel ‘potato’ is at type-level a near neighbour of the context words in this semantic group, but it still tends to form its own cluster, like the orange Cumulus in the figure. This is due both to its frequency and the distinctiveness of its larger cotext, e.g. the co-occurrence with schuif_door ‘to pass on.’ Like other expressions annotated with the ‘hot to the touch’ sense (circles in the figure), including hete hangijzer ‘hot irons’ in yellow and hete adem (in de nek) ‘hot breath (on the neck)’ in light blue, hete aardappel ‘hot potato’ is used metaphorically. In the strict combination of adjective and noun, the meaning of heet proper is still ‘hot to the touch’: it is the combination itself that is then metaphorized (for a discussion see Geeraerts 2003). The context words themselves are frequent and distinctive enough to generate clusters of their own with the tokens that co-occur with them, but aardappel ‘potato’ tends to stick close to the culinary cluster or even merge with it.
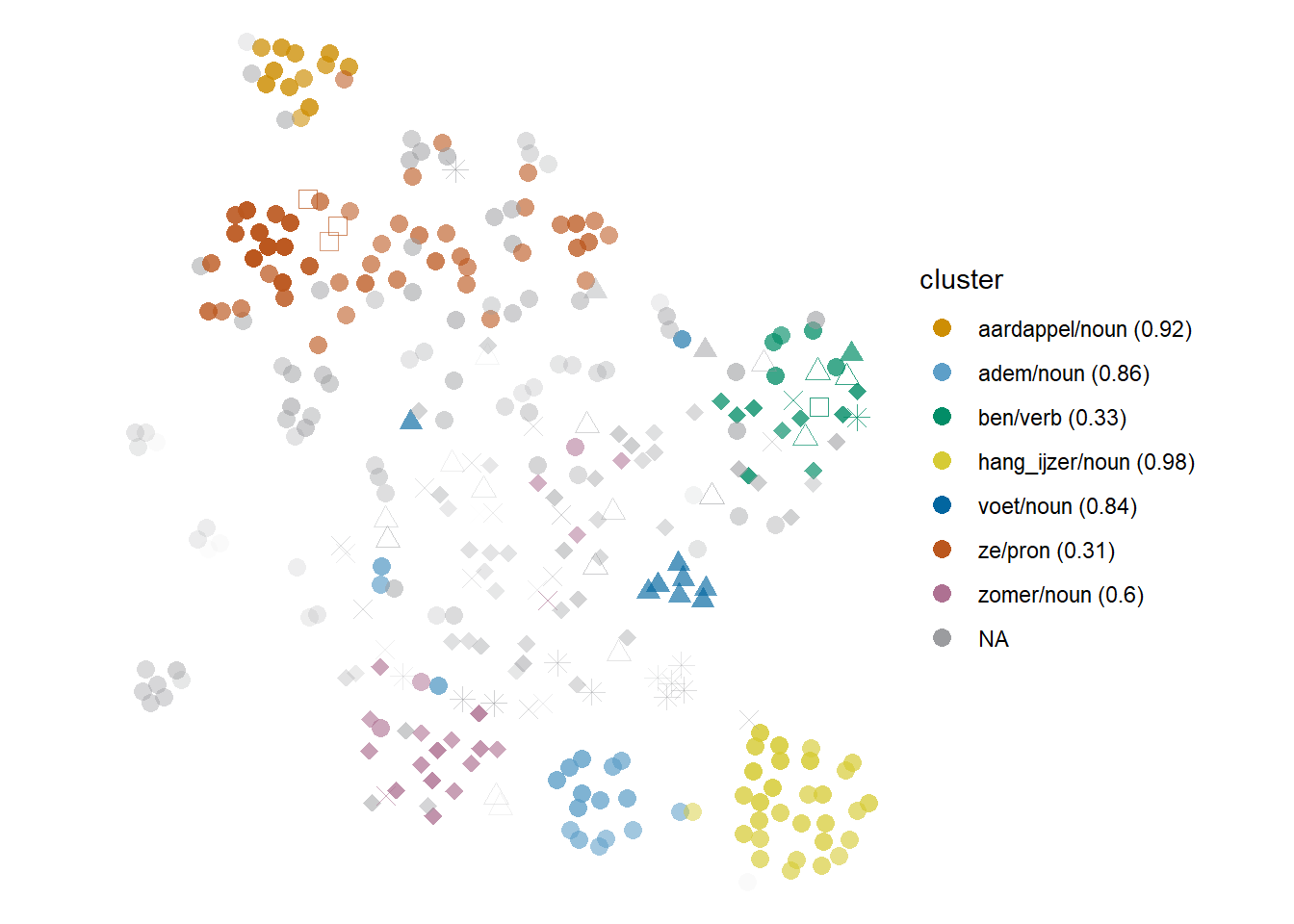
Figure 6.13: Cloud of heet: bound5all-ppmino-focall. Among the literal senses, cricles, filled triangles and filled diamonds represent tactile, weather and body senses; empty squares and triangles represent ‘spicy’ and ‘attractive’ respectively; crosses represent ‘conflictive,’ and asterisks, ‘popular or new.’
6.4.4 Profiling
The adjective geldig ‘valid’ can relate to a legal or regulated acceptability, which is its most frequent sense in the sample, or may have a broader application, to entities like redenering ‘reasoning.’ By definition, and like for most of the lemmas studied here, each sense matches some form of semantic preference. In addition, models of this lemma reveal semantic preference patterns within the frequent, specific sense, each of which, in turns, highlights a different dimension of this sense. These patterns may be only identified as areas in the t-sne plots or, in models like the one shown in Figure 6.14, as clouds.
The green Stratocumulus is characterized by context words such as rijbewijs ‘driving license,’ paspoort ‘passport’ and other forms of identification, as well as verbs like leg_voor ‘to present,’ heb ‘to have’ and bezit ‘to possess.’ In other words, it represents contexts in which someone has to demonstrate possession of a valid identification document, as shown in (35). The light blue Cirrus and the yellow Cumulus, on the other hand, co-occur with other kinds of documents (ticket, abonnement ‘subscription’), euro, the preposition tot ‘until,’ and times (maand ‘month,’ jaar ‘year,’ numbers, etc.). In this case, the price of the documents and the duration of their validity are more salient, as illustrated in (36).
-
Aan de incheckbalie kon de Somaliër echter geen geldige papieren voorleggen. (Het Laatste Nieuws, 2001-08-24, Art. 64)
‘But the Somali could not show any valid papers at the check-in desk.’
-
Klanten van Kunst In Huis zijn bovendien zeker van variatie: wie lid is, kan elke maand een ander werk uitkiezen, het abonnement blijft een leven lang geldig en de maandelijkse huurprijs van 250 frank is ook niet bepaald hoog te noemen. (De Standaard, 1999-05-29, Art. 41)
‘Moreover, customers of Kunst In Huis (lit. `Art At Home’) are guaranteed variation: members can choose a different work each month; the subscription remains valid for a lifetime and the monthly fee of 250 franks is not particularly high either.’

Figure 6.14: Cloud of geldig: bound10lex-ppmiselection-focall. Circles represent the specific sense and triangles, the general one.
6.5 Near-open choice
The clouds described up to now in this chapter can be easily interpreted in terms of dominating context words or semantic domains. We would expect this always to be the case: if hdbscan identifies a cluster, there must be structure; if there is structure, there must be an underlying pattern; if there is an underlying pattern, it can be meaningfully interpreted. Unfortunately, this is not always the case. hdbscan clusters can also be formed in opposition: as we saw before in the case of the Cumulonimbus clouds, i.e. the massive clusters covering at least half the sampled tokens, the grouping criterion might be a negative definition. There is a strong pattern, and everything else that does not conform to it is dumped together. In other situations, whatever structure the hdbscan picks up on is very faint, compared to the Cumulus skies we may find in heffen and hachelijk (see Section 6.2.3). At present, we do not understand the relationship between hdbscan and token-level distributional models well enough to make sense of why these less interpretable clusters emerge and how meaningful they really are.
One of the possible interpretations of these kinds of clusters, from the linguistic point of view, is that some patterns are closer to the “open choice” side of the spectrum, while the cases discussed in Section 6.2 are closer to the “idiom” side. The open-choice and idiom principle were not really presented as poles of a continuum, but they do help as interpretative tool to make sense of the variation in cloud shapes within a lemma and across lemmas. We cannot split the data studied here between models that follow the idiom principle and those that don’t, because the degree to which the distributional behaviour of each lemma can be explained by the idiom principle is different. When we generate a list of collocations for an item, we see the most relevant patterns; when we read sorted concordances, we focus on the similarities that stand out; with token-level distributional models, instead, we can see how strong or weak these patterns are.
In this section we will look at examples of clusters that cannot be interpreted in terms of dominating context words or semantic domains. Most of these result in heterogeneous clusters, especially Cumulonimbus clouds, but they can also, occasionally, bring together all the tokens of senses with certain characteristics. What I have not found is cases of near-open choice clusters that represent semantically homogeneous prototypical contexts.
6.5.1 Heterogeneous clusters
The most common situation in clusters that are not explained by a dominant context word or semantic preference, especially when they are Cumulonimbus clouds, is that they are semantically heterogeneous. These massive clouds occur in models where a small number of tokens that are very similar to each other — typically idiomatic expressions, but not necessarily — stand out as a cluster, and everything else either belongs to the same massive cluster or is noise. In many cases there is barely any noise left, while in others hdbscan does seem to find a difference between the many, varied tokens in the Cumulonimbus clouds and those that are left as noise.
One such example is the Cumulonimbus cloud of blik in Figure 6.15, shown in orange. The small Cumulus clouds to either side are represented by the co-occurrence of werp ‘to throw’ and richt ‘to aim,’ which indicate prototypical instances of blik ‘gaze’ (see (37) and (38)). Very few tokens are excluded as noise — the patterns they form seem to be too different from the clustered tokens to merge with them, but too infrequent to qualify as a cluster on their own.
-
Op zaterdag 27 april zwaait de lokale politie van de zone Kortrijk-Kuurne-Lendelede de deuren wijd open voor al wie een blik wil werpen achter de schermen van het politiewerk. (Het Laatste Nieuws, 2002-04-23, Art. 54)
‘On Saturday 27 April the local police of the Kortrijk-Kuurne-Lendelede zone opens their doors wide for all those who want to have a look behind the scenes of police work.’
-
Maar wat is goed genoeg, zo lijkt Staelens zich af te vragen, haar blik strak naar beneden gericht. (De Volkskrant, 2003-09-27, Art. 170)
‘But what is good enough, Staelens seems to wonder, her gaze looking straight down.’
The orange cluster may seem homogeneous because of the predominance of the circles, but that is simply an effect of the large frequency of the ‘gaze’ sense, which can also occur in contexts like (39). The other sense of the ‘gaze’ homonym, ‘perspective,’ as shown in (40), and of the ‘tin’ homonym (see (41)), are also part of this massive heterogeneous cluster. If anything brings these tokens together, other than the fact that they normally do not match the patterns in (37) and (38), is that they typically co-occur with een ‘a, an,’ de ‘the,’ met ‘with,’ op ‘on,’ and other frequent prepositions, or more than one at the same time. These frequent, partially overlapping, and not so meaningful patterns bring all those tokens together and, to a degree, set them apart.
-
Totdat Walsh met een droevige blik in zijn ogen vertelt dat hij het moeilijk heeft. (Het Parool, 2004-03-02, Art. 121)
‘Until Walsh, with a sad look in his eyes, says that he’s having a hard time.’
-
IMF en Wereldbank liggen al jaren onder vuur wegens hun vermeend eenzijdige blik op de ontwikkelingsproblemen van Afrika. (Algemeen Dagblad, 2001-02-20, Art. 129)
‘The IMF and the World Bank have been under attack for years because of their alledgedly unilateral view on the delevopment issues in Africa.’
-
Zijn vader had een fabriek waar voedsel in blik werd gemaakt. (NRC Handelsblad, 2003-12-05, Art. 120)
‘His father had a factory where canned food (lit. `food in tin cans’) was made.’
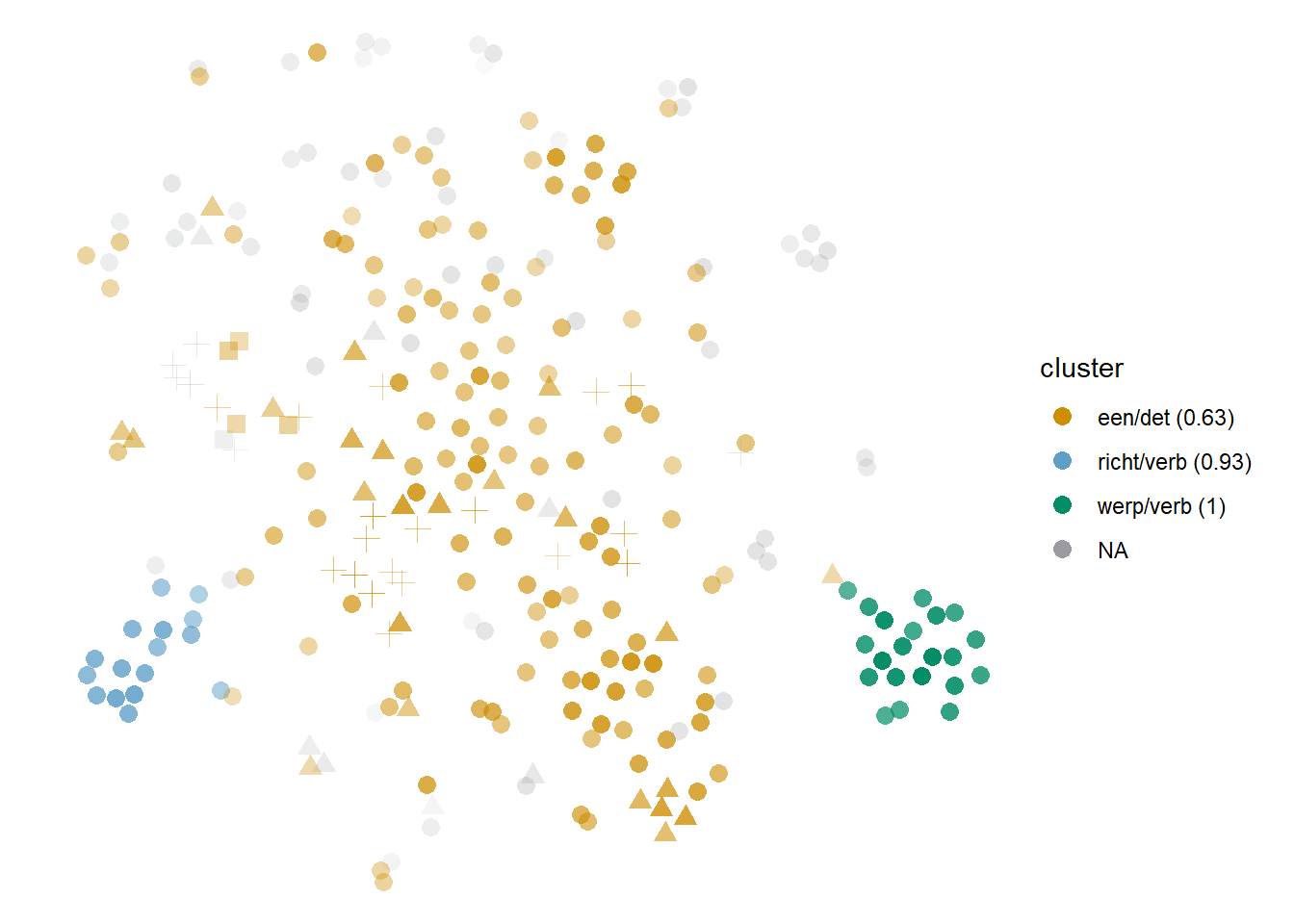
Figure 6.15: Cloud of blik: bound5all-ppmiweight-5000nav. For the first homonym, circles represent ‘gaze’ and triangles, ‘view, perspective’; for the second, squares represent ‘tin’ and crosses, ‘made of tin’ or ‘canned food.’
6.5.2 Dictionary clusters
It might seem pointless to look for meaning in clusters that do not respond to either dominating context words or semantically similar context words, but for some lemmas, it might make sense. Such is the case of the model of huldigen shown in Figure 6.16.
Like with other transitive verbs, the senses of this lemma are characterized by the kind of direct objects they can take. When the direct object of huldigen is an idea or opinion, it means ‘to hold, to believe’: in our sample, typical cases include principe ‘principle,’ standpunt ‘point of view’ and opvatting ‘opinion’ (see examples (42) through (44)). The three of them are near neighbours at type level, but frequent enough to lead their own Cumulus or Stratocumulus clouds in most models, like in Figure 6.16. In other contexts, huldigen means ‘to honour, to pay homage,’ and the role of patient is normally filled by human beings (see examples (45) and (46)). In practice, the variety of nouns that can take this place is much larger than for ‘to believe,’ and as a result, the clusters that cover ‘to honour’ are less compact and defined than the clusters representing the other sense. And yet, the Cumulonimbus shown in yellow in Figure 6.16 almost perfectly represents the ‘to honour’ sense. How is that possible?
-
Jacques: ``Voor het eerst huldigen we het principe dat de vervuiler betaalt." (De Morgen, 1999-03-10, Art. 12)
‘Jacques: ``For the first time we uphold the principle that polluters must pay."’
-
De regering in Washington huldigt het standpunt dat volgens Amerikaans recht de vader beslist over het domicilie van zijn minderjarige zoon. (NRC Handelsblad, 2000-04-03, Art. 97)
‘The government in Washington holds the view that according to American law fathers decide on the primary residence of their underage sons.’
-
…de objectieve stand van zaken in de buitenwereld zou kunnen weerspiegelen. Rorty huldigde voortaan de opvatting dat waarheid synoniem is voor wat goed is voor ons. (De Standaard, 2003-01-09, Art. 93)
‘…would reflect the objective state of affairs in the outside world. Ever since Rorty has held the opinion that the truth is a synonym for what is good for us.’
-
"Elk jaar huldigen wij onze kampioenen en sinds enkele jaren richten we een jeugdkampioenschap in", zegt voorzitter Eddy Vermoortele. (Het Laatste Nieuws, 2003-04-15, Art. 121)
‘"Every year we honour our champions and for a few years we’ve been organizing a youth championship", says chairman Eddy Vermoortele.’
-
Langs de versierde straten zijn we naar de kerk gereden en na de plechtigheid hebben we Karel nog gehuldigd in feestzaal Santro. Hij is nog een heel kranige man. (Het Laatste Nieuws, 2003-07-18, Art. 256)
‘We drove through the ornate streets towards the church and after the ceremony we honoured Karel at the party hall Santro. He is still a spry man.’
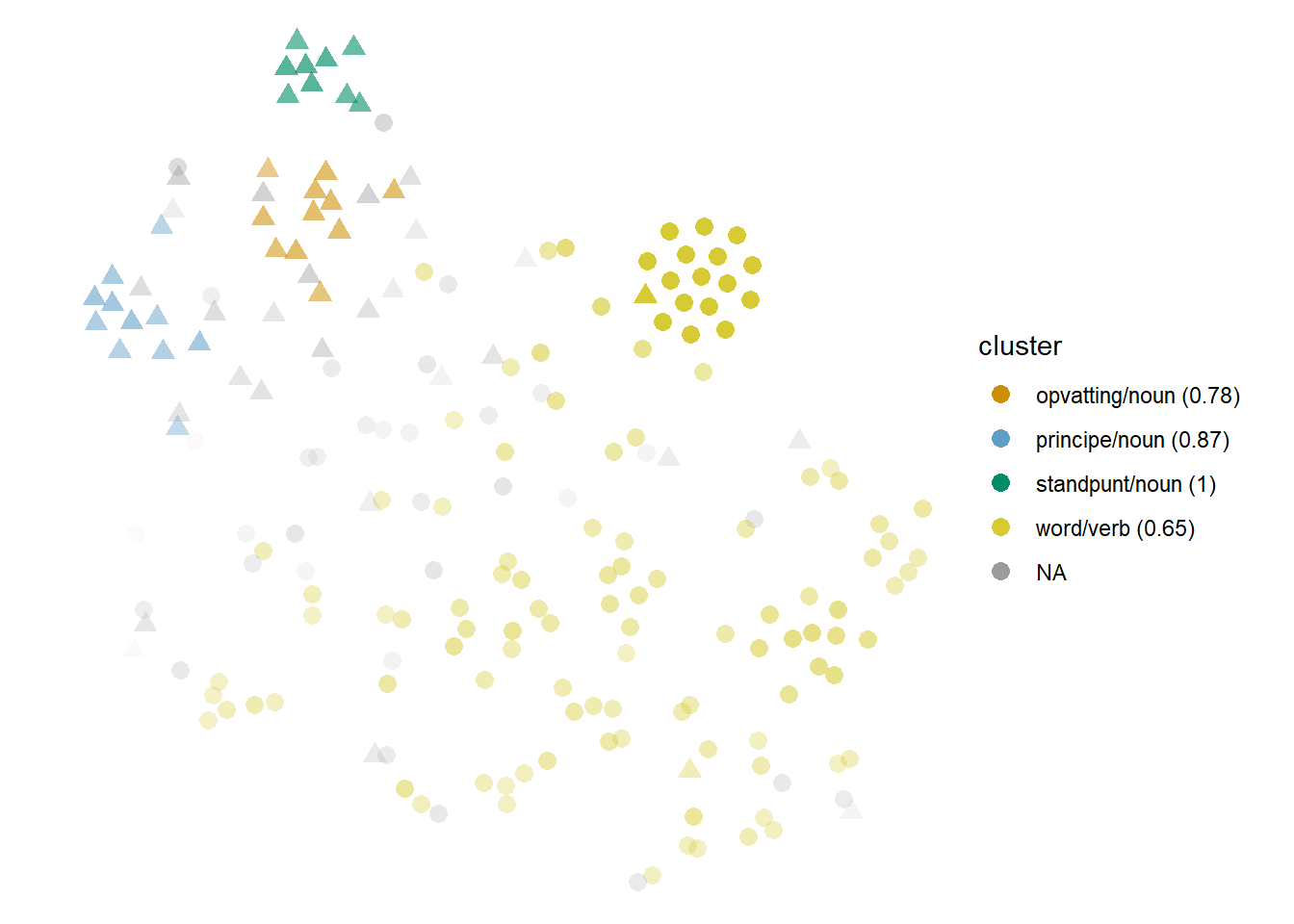
Figure 6.16: Cloud of huldigen: nobound3lex-ppmiselection-focall. Circles represent ‘to believe, to hold (an opinion)’; triangles, ‘to honour.’
One of the factors playing a role in the layout of this model is that the co-occurrences with principe ‘principle,’ standpunt ‘point of view’ and opvatting ‘opinion’ exhaust about half the attestation of the ‘to believe’ sense. The rest of the tokens are too varied and typically fall into noise. The variety within the ‘to honour’ sense cannot compete against the stark differences between these clusters and everything else. Nonetheless, there is some form of structure within the sense that differentiates it from the equally varied remaining tokens of ‘to believe,’ and that is a family resemblance structure.
No single semantic field is enough to cover the variety of contexts in which huldigen ‘to honour’ occurs in our sample: instead, we find different aspects and variations of the prototypical situation of ceremonies organized by sports- and city organizations in public places, in honour of successful athletes. In order to get a better picture of the syntagmatic relationships between the context words within the cluster, we can represent them in a network, show in Figure 6.17. Each node represents one of the 150 most frequent context words co-occurring with tokens from the yellow cloud in Figure 6.16, and it is connected to each of the context words with which it co-occurs in a token of that cluster. The thickness of the edges represents the frequency with which the context words co-occur within the sample; the size of the nodes summarizes that frequency, and the size of the label roughly represents the frequency of the context word among the tokens in the cluster.
The most frequent context word is the passive auxiliary word: it is the only context word captured in the tokens of the dense core on the upper right corner of the cloud, and co-occurs with about half the tokens of this cluster. A number of different, less frequent context words partially co-occur with it, such as kampioen ‘champion,’ stadhuis ‘city hall’ and sport_raad ‘sports council.’ They subsequently generate their own productive branches in the family resemblance network. Crucially, this shows how we might have a token that co-occurs with verdienstelijk ‘deserving’ and sport_raad ‘sports council’ and one that co-occurs with gemeente_bestuur ‘municipal administration’ and officieel ‘official,’ both as part of the same cluster.
Semantically and distributionally, the context words plotted in this network belong to different, loosely related fields, such as sports (kampioen ‘champion,’ winnaar ‘winner,’ sport_raad ‘sports council’), town administration (stad_bestuur, gemeente_bestuur ‘city administration’) and temporal expressions (jaar ‘year,’ weekend). The predominance of the passive auxiliary word — lexically instantiated colligation — the presence of unified semantic fields — multiple semantic preferences — and the family resemblance among tokens, resulting from an intricate network of co-occurrences, work together to model the subtle, complex semantic structure of huldigen ‘to honour.’

Figure 6.17: Network of context words of the huldigen `to honour’ cluster.
6.6 Summary
Different types of clouds offer us different kinds of information. The ideal result of clusters that equal dictionary senses is only rarely found, and instead we typically find collocations that represent (proto)typical contexts within a sense. Next to this typical result, we encounter a variety of phenomena combining syntagmatic and paradigmatic aspects. Along with collocations, we find colligation and semantic preference as motors behind most of the clusters, but also a number of cases where no clear distributional pattern can be found. These phenomena correlate decently with the types of clouds discussed in Chapter 5: collocations with Cumulus clouds, lexically instantiated colligation with Stratocumulus clouds, semantic preference with all but Cumulonimbus, and near-open choice with Cumulonimbus. These are, of course, not deterministic mappings, but general tendencies. At the paradigmatic or semantic level, next to clusters that represent typical contexts, we find heterogeneous clusters and some that match senses completely. In addition, typical contexts may include richer information regarding different semantic dimensions of a sense that are highlighted in certain contexts, i.e. that are prototypical of that contextual pattern.
In this chapter we have seen the different combinations of these syntagmatic and paradigmatic phenomena, and the shapes they can take in the models of different lemmas. Clouds do not necessarily match senses, but may offer us other types of information, depending on the distributional properties of the lemma and the dimensions that are most relevant in its semasiological structure. In the following chapter we will look at the (lack of) relationship between the information we obtain and parameter settings.